

프로세스 마이닝을 통한 비용 배분과 절감
- 작성일2021/12/29 16:05
- 조회 1,040
사례 요약(Summary)
글락소스미스클라인 (GlaxoSmithKline, GSK)은 혁신적인 치료제, 백신, 소비자 건강관리 제품의 연구개발을 선도하는 글로벌 헬스케어 기업입니다. 최근 GSK는 ‘코로나19’ 신약 개발에 3천억을 투자했습니다. 제조 생산성을 향상하기 위해 GSK는 데이터과학, 인공지능, 전통적인 지속 개선법을 사용하고 있습니다. GSK는 ERP 시스템의 품질관리 데이터를 활용하고, 지속 개선 방법론(continuous improvement methodology)을 프로세스 마이닝 및 머신러닝과 결합하여 프로세스 변동이 비용에 미치는 영향을 이해했습니다.
위의 과정을 통한 학습은 무척 의미가 깊었습니다. 또한 다양한 알고리즘을 갖춘 결과모델을 통해 GSK는 이제 프로세스 인스턴스의 비용을 이해할 수 있습니다. 프로세스 마이닝과 Disco 소프트웨어 사용은 프로세스의 변동을 이해하는 데 필수적이었습니다.
프로세스 마이닝을 채택하고 LDA(Latent Dirichlet Allocation, 문서를 모델링하는 기법)와 GBT(Gradient Boosted Tree, 회귀와 분류 문제를 위한 머신러닝 기법) 및 수많은 SQL(Structured Query Language) 쿼리와 같은 추가 데이터과학 기법을 적용함으로써 제조과정에서 프로세스 비용을 이해하는 방식을 변화시킬 수 있음을 알게 되었습니다. 해당 모델을 통해 GSK는 (프로세스) 변동이 약물 및 의약품 비용에 어떤 영향을 미치는지 이해했습니다.
또한 이번 프로젝트를 통해 GSK는 데이터과학과 인공지능을 조직에 적용할 수 있는 디지털화 투자 방안을 학습하게 되었습니다. 데이터과학 프로젝트 수행을 통해 GSK는 피처 공학(feature engineering)(1), 부서간 데이터 격차 조정, 새로운 모델링 및 추가 데이터 출처를 도입하여 (기존에 구축된) 모델을 확대합니다. 구조화된 데이터와 비구조화된 데이터를 함께 작업하는 방식을 학습하는 것은 비즈니스 성과에 대한 폭넓은 이해에 도움을 줍니다.
대상 기업
GSK는 사람이 더 많은 일을 하고, 건강해지고, 더 오래 살도록 돕는 특별한 목적을 가진 과학 주도의 글로벌 헬스케어 회사입니다.
GSK의 목표는 세계에서 가장 혁신적이고 성능이 탁월하며 신뢰할 수 있는 헬스케어 회사 중 하나가 되는 것입니다 [1]. 우리의 전략은 가능한 한 많은 사람들에게 차별화된 고품질의 필수 의료 제품을 제공하는 것입니다. 과학기술 노하우와 유능한 인재를 통해 우리는 3개의 글로벌 비즈니스(즉, 제약, 백신, 소비자 헬스케어)에서 이러한 전략을 실현하고 있습니다 [2].
GSK의 CEO가 설명하는 성과목표 중 하나는 “비용과 현금 생성의 통제에 집중하는 것”입니다 [3]. “2018년에 우리는 3가지 주요 영역(즉, 과학 및 기술을 사용하여 건강 요구를 해결하고 제품을 보다 저렴하고 가용성 있게 하며 현대적인 고용주가 된다)에 중점을 둔 신뢰 구축을 위한 새로운 공약을 발표했습니다.” [4]
GSK의 3가지 글로벌 비즈니스에서 우리는 폭넓은 제품 범주와 기술을 보유하고 있습니다. 프로세스 마이닝을 활용한 비용 배분(Cost Deployment)(2) 프로젝트는 ‘제약’ 비즈니스에 초점을 두고 수행되었습니다.
분석 프로세스
지속 개선 기능부서는 DD&A(Digital, Data and Analytics) 내에서 프로세스 마이닝 프로젝트의 사용 사례와 분석 주제를 찾았고, 해결해야 할 몇 개의 과제를 제시했습니다. 예를 들어, 프로세스 마이닝은 트랜잭션 데이터를 사용하여 “비용 배분” 관점을 제공할 수 있는가? 표준 프로세스가 규범 경로(normative path)를 벗어나서 수행되는 방식을 이해할 수 있는가? 이러한 표준 경로 이탈은 비용에 영향을 주는가? 표준화에서 벗어나는 예외는 무엇인가? 프로세스 마이닝은 추가적인 낭비와 비부가가치 액티비티를 식별할 수 있는가?
[one_second][blockquote author="" link="" target="_blank"]비용 배분은 월드 클래스 제조에서 나온 방식으로, 100%의 비용을 기준으로 조직의 손실 비용을 이해하기 위해 산업공학 접근법을 취합니다.[/blockquote]- Kevin Joinson, GSK[/one_second]
[one_second]비용 배분은 월드 클래스 제조에서 나온 방식으로, 100%의 비용을 기준으로 조직의 손실 비용을 이해하기 위해 산업공학 접근법을 취합니다. 이를 위해 프로세스에 비용이 할당되고 부가가치 작업과 비부가가치 작업 및 원인과 결과가 구분됩니다.[/one_second]
GSK는 보다 저렴하고 사용 가능한 제품의 제공을 강조하기 때문에 이러한 과제는 GSK의 우선순위와 일치합니다. 프로세스 비용을 명확하게 이해함으로써 제품을 보다 저렴하게 만드는 최상의 결과를 가져올 수 있는 올바른 영역에 주목할 수 있습니다.
이 프로젝트의 파일럿을 위해 품질관리 프로세스를 선정했습니다. 품질관리가 개선되면 제품 품질이 향상되고, 제품 가격이 저렴해지고, 서비스가 개선되며 환자와 소비자를 위한 가용성이 증가합니다.
활용 데이터
이 데이터과학 프로젝트의 노력 중 80%는 데이터 준비 및 처리와 관련되어 있습니다. 이러한 데이터 준비 작업은 추출, 모델링, 저장, 데이터 변환, 결측 데이터 처리, 데이터 구성에 영향을 주는 프로세스 변경 처리를 포함합니다. 대부분의 데이터는 ERP 시스템에서 가져왔습니다. 또한 일부 외부 데이터가 모델을 지원하기 위해 추가되었습니다. 데이터 변환에 가장 많은 노력이 필요했습니다. 예를 들어, ERP에서 원시 데이터를 가져와서 분석을 시작할 수 있도록 데이터를 변환하려면 70개 이상의 SQL 쿼리가 필요했습니다.
이 프로젝트의 한 가지 도전과제는 약과 의약품 제품의 범위가 광범위하다는 것입니다. ERP에서 프로세스는 동일하지만 작업과 관련된 비용은 크게 다를 수 있습니다. 따라서 분포 모델을 적용해야 했습니다.
ERP 거래 데이터의 또 다른 도전과제는 액티비티에 대한 ‘시작’ 타임스탬프가 거의 없다는 것입니다. 일반적으로 사람은 작업을 수신한 후에 현장에 가서 해당 작업을 수행(실제 수행시간)합니다. 그런 다음에 ERP 시스템에 로그인해서 동시에 해당 작업 완료 액티비티를 수행합니다. 따라서 데이터에서 ‘종료’ 타임스탬프만 얻을 수 있습니다.
접근법
가치를 식별하고 신속하게 전달할 수 있는 민첩한 경로를 따를 수 있도록 우리는 “데이터 마이닝을 위한 산업간 표준 접근법(CRISP-DM: Cross-industry standard process for data mining)(3)”을 프로젝트에 적용했습니다.
단계 1: 비즈니스 이해
우리는 처음에 광범위한 약과 의약품을 생산하는 단일 제조 현장과 협업했습니다. 필요한 데이터 오브젝트를 이해하기 위해 품질프로세스의 주제 전문가(SME: Subject Matter Expert)와 협력했습니다. 그들은 내부 및 외부 비즈니스 프로세스를 설명했습니다. 이를 통해 데이터에서 프로세스 비용의 모든 측면을 모델링할 수 있었습니다 (익명 처리된 대략적 개요가 <그림 1>에 제시되어 있음).
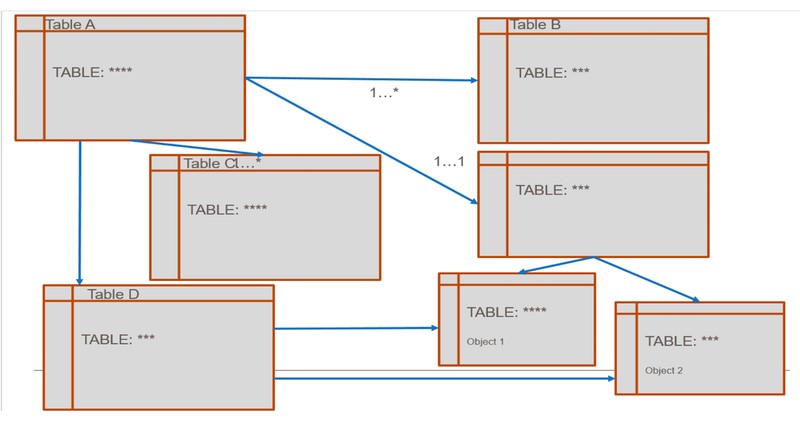
<그림 1> 비용 배분 범위를 위한 데이터 모델과 추출
단계 2: 데이터 수집
그런 다음에 프로세스 오브젝트와 관련된 모든 필드를 내보내서 ERP에서 원시 데이터를 추출하고 데이터 스키마를 생성했습니다. 프로세스 소유자와 협력하여 프로세스에서 어떤 변경 사항이 발생했고, 이들이 발생한 때를 이해하는 것이 중요합니다. 이러한 협력을 통해 일관된 데이터셋을 확보할 수 있었습니다. 예를 들어, 우리는 Disco에서 시간의 경과에 따른 액티비티들의 변화를 살펴봄으로써 프로세스가 언제 단순화되었는가를 알 수 있었습니다.
단계 3: 데이터 준비
데이터 준비는 여러 단계로 수행되었으며 일관된 모델을 찾기 위해 많은 시행착오와 반복적 접근방식을 취했습니다. 첫 번째 단계는 프로세스 마이닝 분석에 요구되는 핵심 필드(케이스ID, 액티비티, 리소스, 타임스탬프(4))를 포함하는 이벤트 로그를 작성하는 것입니다. 그런 다음 프로세스의 출처가 다양하기 때문에 품질관리 프로세스를 분류해야 했습니다.
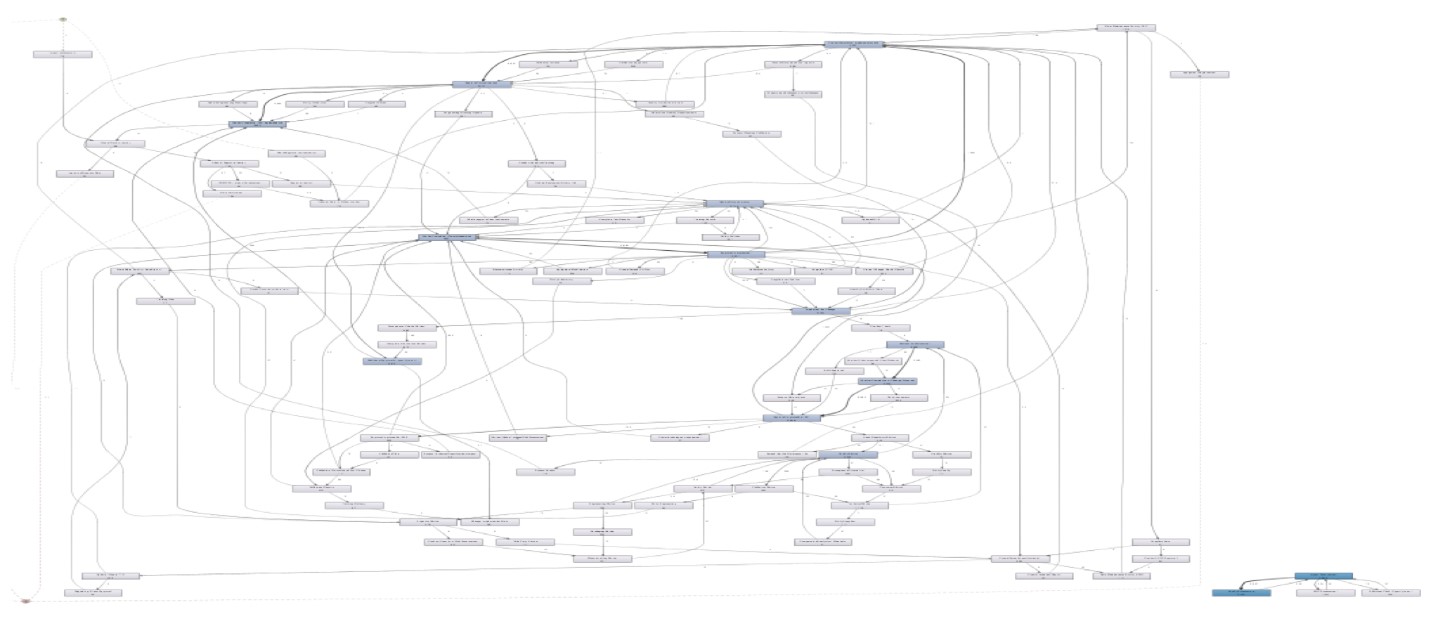
<그림 2> 스파게티 모델
한 가지 도전과제는 일부 액티비티들이 구조화되지 않은(“자유 형식의 텍스트”) 액티비티 이름을 가진다는 것입니다. 이로 인해 프로세스 맵에서 다양한 액티비티들이 발생하여 스파게티 모델 뷰가 생성되었습니다(<그림 2 참조).
이 도전과제를 극복하기 위해 LDA(Latent Dirichlet Allocation) 자연어 처리 알고리즘을 적용했습니다. 분석된 자유 형식 액티비티 이름에 기반을 둔 토픽 분류(topic classification)가 결과로 도출되었습니다. 이 분류를 통해 여러 토픽과 관련된 다양한 유형의 품질관리 프로세스를 구분할 수 있었습니다. GBT(Gradient Boosted Tree)를 추가로 적용하여 일부 토픽의 예상 수행기간(duration)에 대한 매우 높은 신뢰도를 얻었습니다. 이를 통해 우리는 종료 시간에 대한 예측을 이미 제공할 수 있었습니다. 그러나 일부 토픽에 대해서는 신뢰도가 낮았으므로 추가 분석 및 이해를 위해 관련 케이스ID들을 살펴보았습니다(<그림 3> 참조).
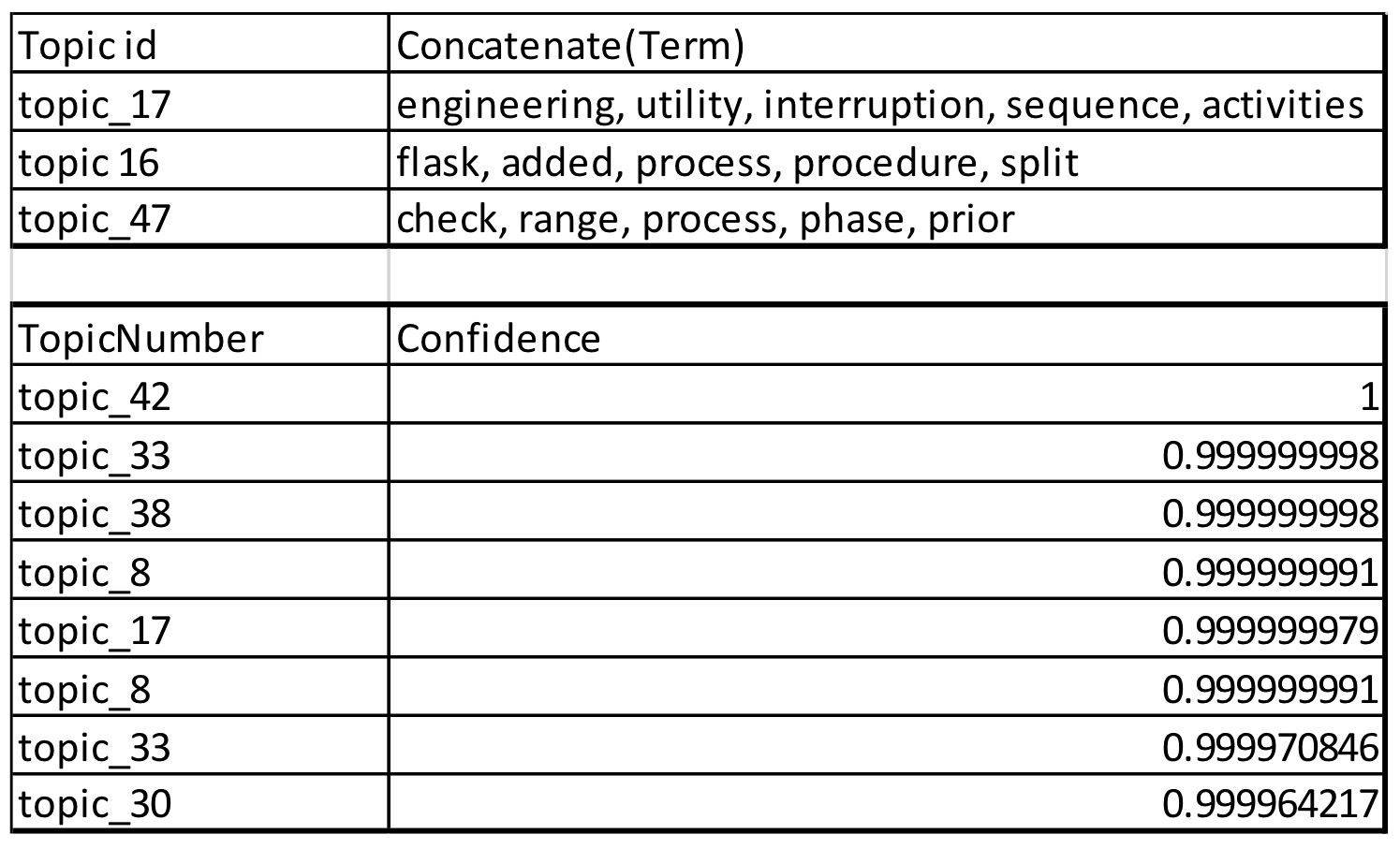
<그림 3> 발견한 토픽과 신뢰구간
그룹화가 논리적이고 잘 표현되었음을 보장하기 위해 비즈니스 프로세스 주제 전문가와 함께 토픽 발견을 검증했습니다. 이 검증 후에 케이스ID와 분류 사이에 적절한 연결을 얻었습니다. 그런 다음 새로운 분류를 원시 데이터에 추가하고 Disco에서 베리언트를 분석하여 이러한 클래스의 프로세스 베리언트를 이해했습니다(<그림 4> 참조).
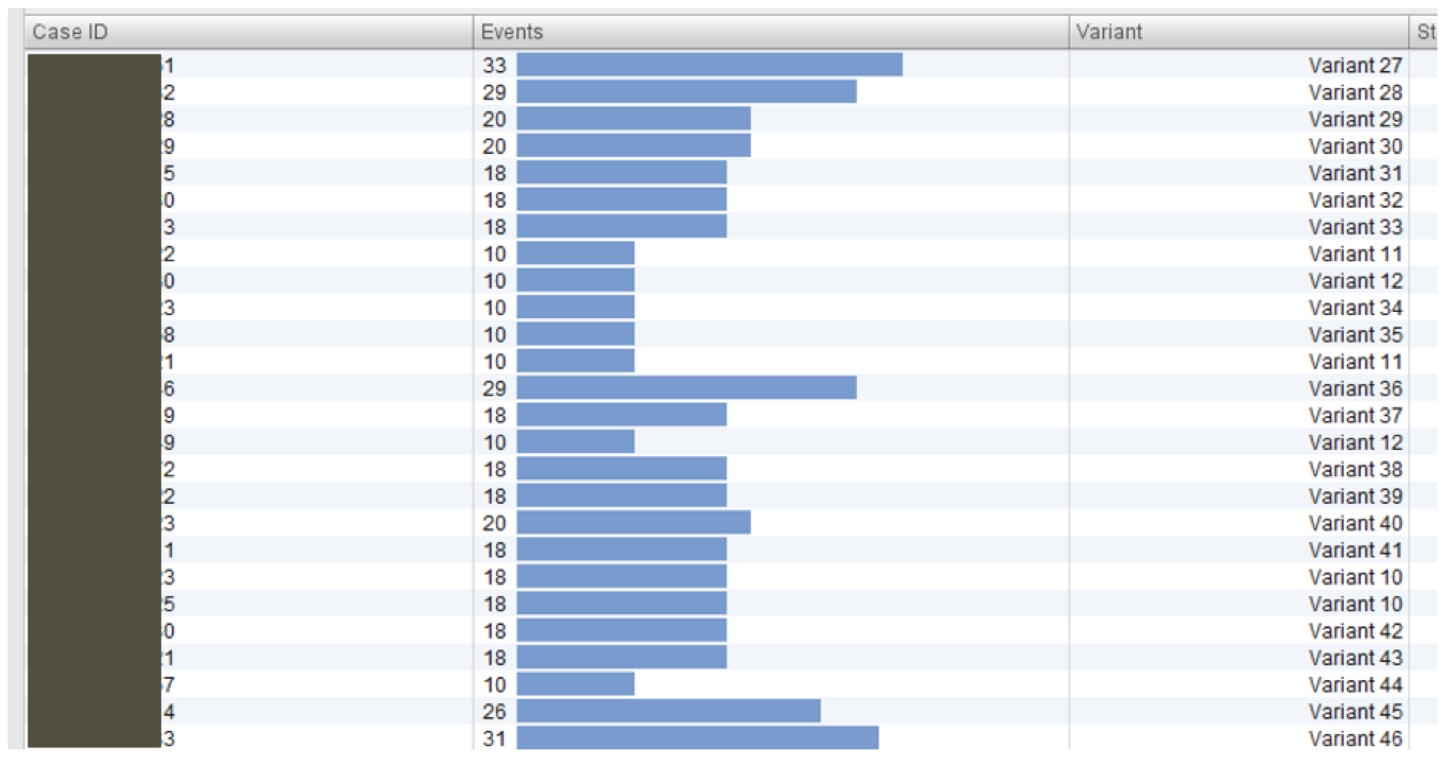
<그림 4> 품질관리 프로세스의 클래스와 관련 베리언트
여러 클래스에 대한 프로세스를 분석한 후 발생한 액티비티들을 이해했습니다. 많은 경우에 하나의 타임스탬프만으로 프로세스 마이닝을 수행할 수 있습니다. 하지만 비용 분석을 위해 서비스 시간 차원이 필요했습니다. 그래서 우리는 이러한 결측 데이터를 원시 데이터에 추가해야 했습니다. 우리는 프로세스 주제 전문가와 함께 클래스와 액티비티를 검토했고 그들의 도메인 지식에 기반을 두고 각 작업에 서비스 시간을 할당했습니다. 그런 다음 추정된 서비스 시간을 기준으로 누락된 시작 타임스탬프를 소스 데이터에 추가했습니다. 이러한 과정을 통해 Disco를 활용한 프로세스 마이닝 분석에 사용할 수 있는 완전한 이벤트 로그를 가지게 되었습니다.
단계 4: 모델링
이제 프로세스 변동에 기반을 둔 비용 구조를 모델링할 수 있는 데이터가 준비되었습니다. Disco에서 프로세스 정보를 내보내어 데이터베이스에 탑재했습니다. 그런 다음 프로세스 클래스와 베리언트의 비용을 결정하기 시작했습니다. 이러한 모델링은 대단한 성과였습니다. 비용에 대한 정확한 관점을 제공하기 위해 70개 이상의 SQL 문이 필요했습니다. 모델링의 일부는 비용 요인으로 작용하는 외부 재무 데이터를 가져오는 것이었습니다. 또한 이 모델은 이벤트 로그가 데이터베이스에 코딩되어 Disco에 대한 새로운 로그를 제공하기 위해 데이터를 새로 고칠 수 있게 했습니다(<그림 5> 참조).
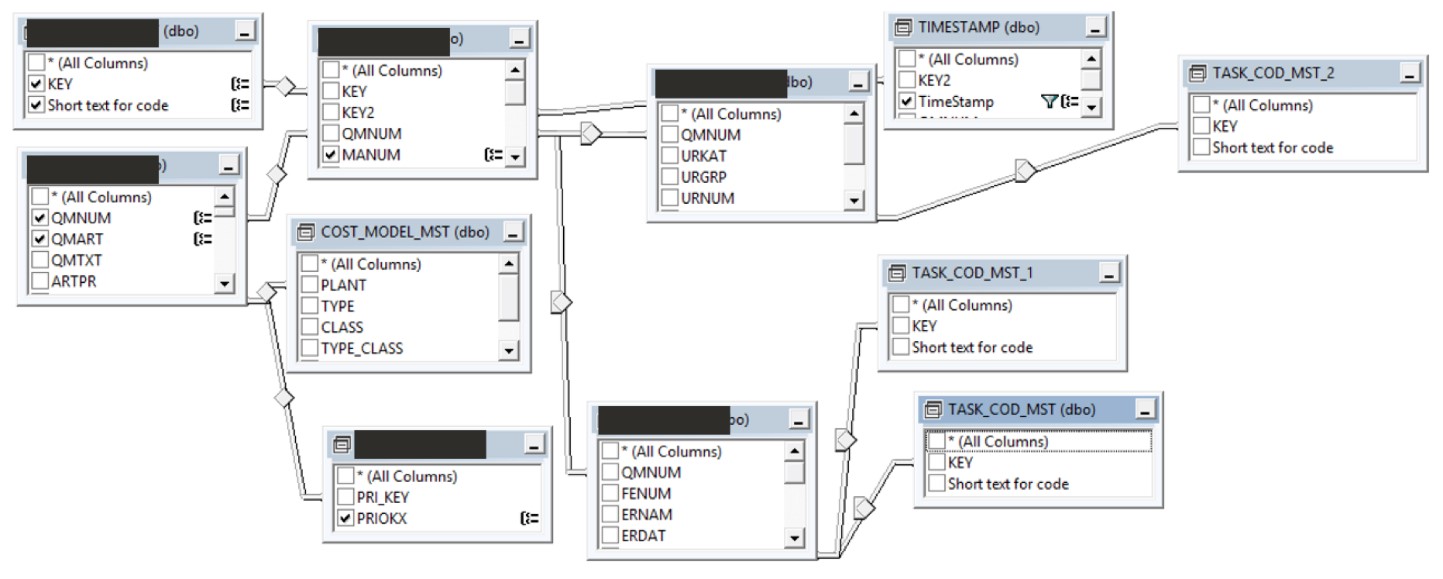
<그림 5> Disco를 위한 SQL 이벤트 로그
단계 5: 평가
그런 다음 검증된 모델이 실무에 활용되었습니다. 모든 제약 사이트에 동일한 요소가 적용됨에 따라 이제 비용 절감 기회에 대한 전반적인 관점을 보유하게 되었습니다. 제조 현장은 모델의 정보와 통찰력을 활용하고 있습니다. 그들은 Disco를 사용하여 개선할 영역을 강조합니다. 매달 몇 번의 클릭으로 데이터가 새로 고쳐집니다.
변환의 전반적 과정
[one_second][blockquote]모든 제약 사이트에 동일한 요소가 적용됨에 따 이제 비용 절감 기회에 대한 전반적인 관점을 보유하고 있습니다.
- Kevin Joinson, GSK[/blockquote][/one_second][one_second]데이터 변환의 전반적 과정이 <그림 6>에 제시되어 있습니다. 앞에서 설명한 것처럼, 주제 전문가와의 협업은 여러 단계(예, 최초 이해와 분류된 토픽의 검증, 서비스 시간의 추정, 전체 결과의 검증)에서 필수적이었습니다.
[/one_second]
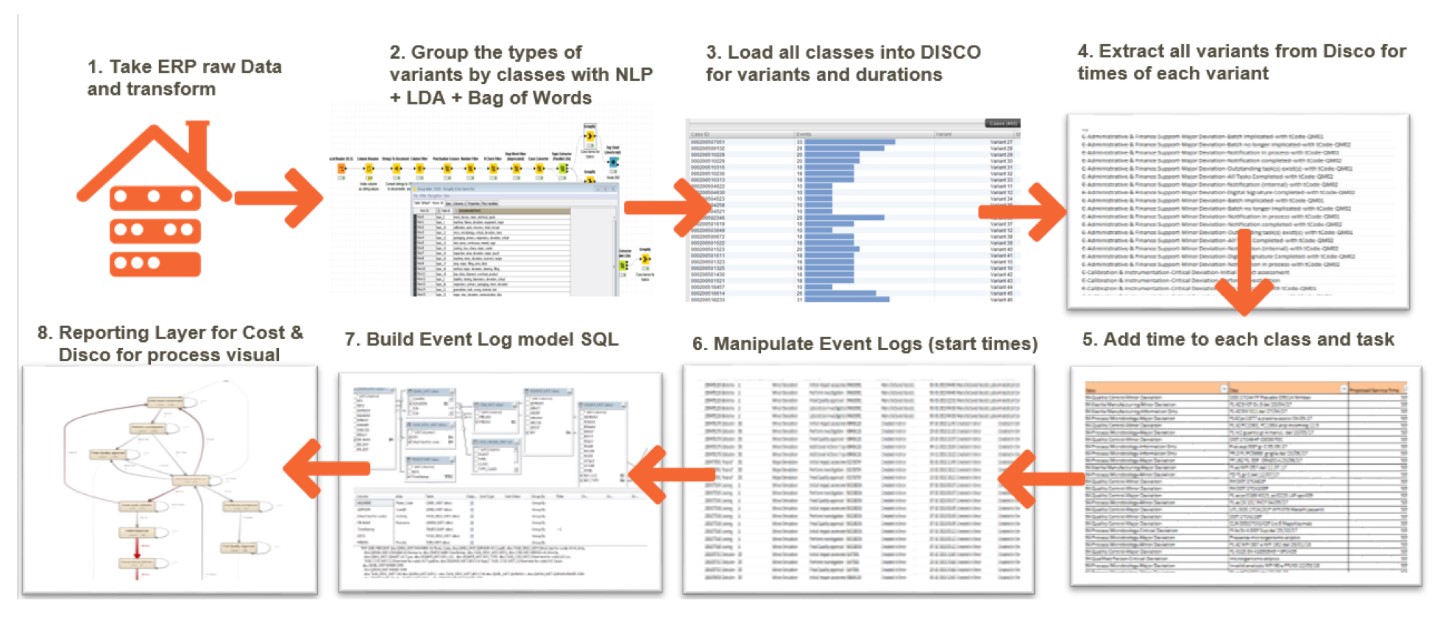
<그림 6> 데이터 과학으로 프로세스 비용을 모델링하는 단계
비즈니스 효과
이 분석을 통해 우리는 기준 성과에서 37%의 향상을 달성하는 집중적인 개선 이니셔티브를 지원했습니다(<그림 7> 참조). 우리의 방법은 현재 다양한 프로세스에 걸쳐 광범위한 제조 네트워크에서 사용되고 있습니다.
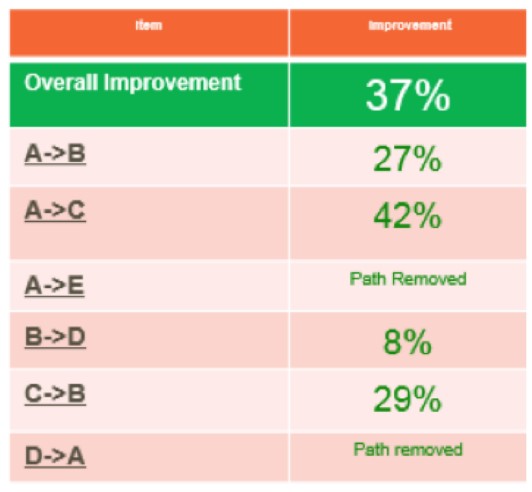
<그림 7> 개선 성과 요약 테이블
비용 절감을 위해 프로세스에서 낭비를 제거해야 합니다. 이 사례 연구에 나타난 것처럼, 프로세스 마이닝은 이런 최적화를 지원하는 핵심 도구입니다.
이에 더해 GSK는 프로세스 완료까지 남은 시간의 예측에 인공지능을 적용하고 있고, 딥러닝과 시맨틱 텍스트 유사성(Semantic Textual Similarities)을 사용하여 품질 전문가를 지원하고 있습니다. 프로세스의 낭비를 제거하는 것은 머신러닝과 같은 고급 데이터과학 기법들의 지속적인 사용을 위한 토대를 제공합니다.
결론
다른 데이터과학 기술과 함께 사용한 프로세스 마이닝을 통해 GSK는 ERP 데이터를 이용하여 프로세스 및 (프로세스) 변형의 비용 메커니즘을 이해할 수 있었습니다. 이때의 도전과제는 1차 목적으로만 사용되는 중요한 데이터를 재사용하기 위해 구조화된 데이터와 비구조화된 데이터를 결합하는 방법입니다. 이러한 데이터 재사용을 통해 성과 향상 방법을 더 잘 이해할 수 있을 뿐만 아니라 데이터 중심으로 지속적인 개선을 추진할 수 있었습니다.
참고문헌
[1] Anon. GSK Annual Report 2018. https://www.gsk.com/en-gb/about-us/ Access online June 2019
[2] Anon. GSK Annual Report 2018 https://www.gsk.com/media/5349/annual- report-2018.pdf Page 2. Access online June 2019
[3] Emma Walmsley. GSK Annual Report 2018. https://www.gsk.com/media/5349/annual- report-2018.pdf Page 3. Access online June 2019
[4] Emma Walmsley. GSK Annual Report 2018. https://www.gsk.com/media/5349/annual- report-2018.pdf Page 4. Access online June 2019
(1) 머신러닝 알고리즘을 적용하기 위해 데이터에 대한 도메인 지식을 활용하여 특징(feature)을 만들어내는 과정을 말함
(2) 비용 배분은 제조 프로세스의 다양한 측면에 기인한 비용을 보다 잘 이해하기 위해 사용됨. 제조업체는 비용 배분을 사용하여 제조 프로세스에서 개선이 필요한 영역을 효과적으로 평가할 수 있음. 제조 프로세스를 더 작은 조각으로 세분하여 생산을 개선하기 위해 손실에 대한 특정 원인을 식별하고 제거할 수 있음. 이때 제조업체는 재무 데이터를 기반으로 각 조각에 특정 비용을 할당함
(3) 별도의 프로세스 마이닝 방법론이 있으나, GSK는 익숙한 CRISP-DM 방법론을 적용함
(4) CaseID, Activity, Resource, Timestamp(CART) 중 Resource 필드는 생략될 수 있음