

프로세스 마이닝과 시뮬레이션의 결합
- 작성일2021/12/29 15:58
- 조회 1,839

위의 사진에서 우주비행사 Christer Fuglesang는 국제 우주 정거장(International Space Station)으로의 19번째 셔틀 미션을 위해 예정된 선외 활동에 대비한 수중 시뮬레이션에 참가하고 있다. 그는 이런 시뮬레이션을 통해 모든 과정을 자연스럽게 습득하여 실제상황에서 어떠한 실수도 하지 않으려고 한다.
만약 조직에서도 실제로 어떤 변화를 꾀하기 전에 프로세스 개선 효과를 “시험(try out)”해 볼 수 있다면 어떨까? 만약 여러분의 프로세스에 가져올 수 있는 가능한 변화들에 대한 대안이 될 수 있는 “what-if” 시나리오들의 효과를 비교해서 최선책을 찾을 수 있다면 어떨까?
사람들은 가끔 Disco 툴이 프로세스를 구성하는 한 단계를 없애거나 흐름 시간의 일부를 줄이는 것의 효과를 시뮬레이션 할 수 있는가를 물어본다. 단지 입력데이터를 변경하고 분석을 재실행함으로써 간단한 시나리오들에 대해서는 Disco를 이용해서 시뮬레이션을 수행할 수 있다. 하지만 더욱 정교한 시나리오들에 대해서는 좀 더 정교한 시뮬레이션 기법들을 이용할 필요가 있다.
“시뮬레이션은 시간의 경과에 따른 실제 세계 프로세스나 시스템 작동의 모방이다.”
활용 가능한 많은 성숙된 시뮬레이션 도구들이 존재하는데 반하여 가장 큰 도전들 중의 하나는 시뮬레이션 수행을 위한 정확한 기본 모델을 생성하는 것이다. 만약 그 모델이 결함을 가지고 있다면 여러분의 시뮬레이션 결과도 잘못 나올 것이다.
그리고 프로세스 마이닝이 이 부분에서 도움을 줄 수 있다. 프로세스 마이닝은 여러분의 프로세스가 실제 어떤 모습이고 각각의 활동이 얼마나 걸릴 것인가를 가정하기보다는 여러분의 프로세스 흐름에 대한 객관적인 정보(지연과 가용성 포함)를 제공한다. 이러한 정보는 현실을 더욱 정확하게 반영한 시뮬레이션 모델을 만드는데 활용될 수 있다.
프로세스 마이닝과 시뮬레이션은 아주 잘 통한다. 프로세스 마이닝 소프트웨어인 Disco와 예측 시뮬레이션 회사인 Lanner사의 시뮬레이션 소프트웨어인 Witness 와의 연계를 탐색하기 위해서 Fluxicon사의 Anne은 Lanner사의 Geoff Hook과 팀을 이루었다.
프로세스 마이닝과 시뮬레이션의 연계가 어떻게 보이는가에 대한 간단한 예제 시나리오가 다음과 같다.
단계 1: 실제 프로세스의 발견
만약 여러분이 은행의 신용카드 신청 프로세스의 관리자라고 하자. 이 프로세스가 실제적으로 어떻게 흘러가는지를 이해하기 위해서 Anne과 Hook는 대상 IT 시스템에서 데이터를 추출했고 프로세스 마이닝을 수행했다.
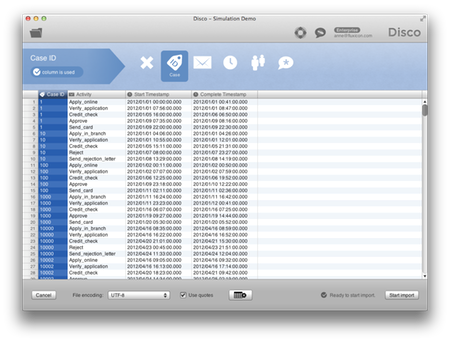
첫 단계는 신용카드 신청 프로세스를 지원하는 IT 시스템에서 추출된 데이터를 Disco에 올렸다. 이 예제에서 그들은 단지 4개의 칼럼만을 이용했다. 즉, case ID (the application number), 활동 이름, 각 활동 별 시작과 완료 시간. Disco는 이러한 칼럼들을 자동적으로 인식해서 구성한다.
‘Start Import’ 버튼을 누르면 Disco가 프로세스 맵을 자동적으로 생성해 준다.
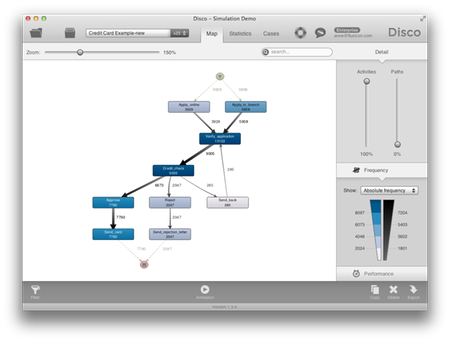
우리는 생성된 프로세스를 얼마나 자세하게 보기를 원하는가를 결정할 수 있다.
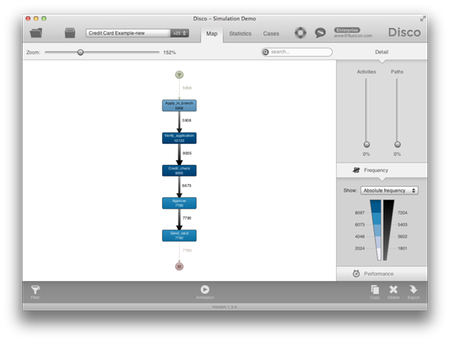
그리고 빈도수는 각 경로가 실제 상황에서 얼마나 자주 활용되었는가를 나타내어 준다.
케이스 기간(신용카드 신청 처리 기간)이 분석되어 어떤 신청 사례들은 17일까지 걸림을 알 수 있다. 사실, 신청 사례들의 90%는 9일 이상 걸렸다. 문제는 다른 은행들은 빨리 처리해 주기 때문에 고객들이 다른 은행들로 옮겨가기 시작했다는 것이다.
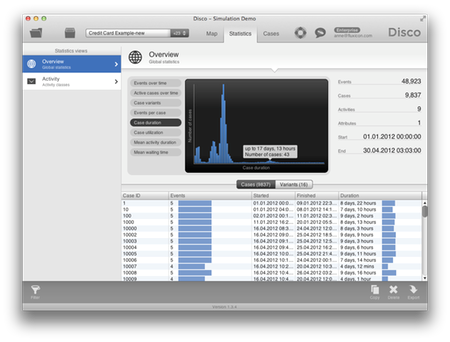
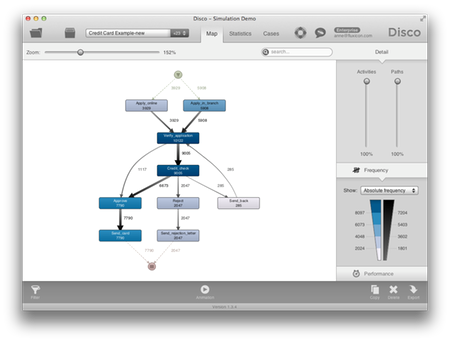
프로세스 맵의 성과 관점에서 우리는 병목이 어떤 곳에서 발생함을 알 수 있다. 예를 들어, 신용 체크 단계는 평균 4.2일 걸려서 지연되고 있음을 알 수 있다.
프로세스 마이닝은 이탈(deviation), 재 작업(rework), 병목을 포함한 실제 프로세스 흐름을 보여준다. 이탈, 재 작업, 병목은 비 가치 창출 활동으로서 제거나 개선의 대상이 되는 활동들이다. 더욱이, 프로세스 마이닝은 선택된 프로세스 경로의 빈도에 관한 객관적인 정보와 활동들의 수행 시간과 프로세스 내의 지연시간에 관한 객관적인 정보를 제공한다.
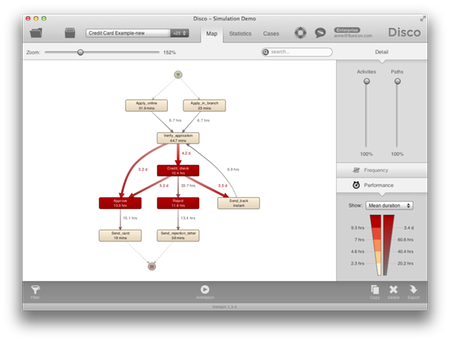
단계 2: 현재 프로세스에 대한 시뮬레이션
앞에서 설명한 모든 것이 시뮬레이션을 시작할 때 활용될 수 있는 유용한 정보이다. 백지에서 시뮬레이션 모델을 생성하는 대신에 그들은 현재 프로세스에 대한 시뮬레이션 모델을 생성하기 위해서 위에서 발견된 프로세스를 재활용하기를 원했다.
현재 프로세스를 시뮬레이션하는 것은 더 많은 이해와 통찰을 제공한다. 그러나 궁극적인 목표는 대안이 될 수 있는 ‘to-be’ 시나리오들의 성과를 예측하기 위해서 검증된 시뮬레이션 모델을 이용하려고 하는 것임을 기억하자.
Lanner 사와의 프로토파입 프로젝트에서 그들은 Disco에서 엑셀 파일 형식으로 데이터를 추출했다. 시뮬레이션 소프트웨어인 Witness 프레임워크 모델은 이러한 데이터를 받아들여서 엑셀에 정의된 활동, 경로와 시간 데이터를 자동적으로 기초화하였다. 이 프레임워크 모델은 또한 시뮬레이션된 성과를 측정하기 위한 몇몇의 KPI를 가지고 있는데 이것은 다시 엑셀로 추출이 가능하다.
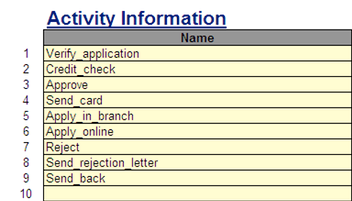
요구되는 데이터의 예가 아래에 제공된다.
(Activities: 모델에 포함된 각 활동에 대한 정의)
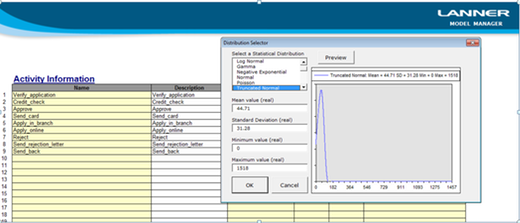
(Activity Times: 시뮬레이션을 위한 프로세스 시간들을 생성하기 위한 유효한 수단을 제공하기 위해서
분포들이 프로세스 수행에서 정의될 수 있다.)
(Routings: 확률들은 모델에 있는 경로를 정의하기 위해서 이용된다.)
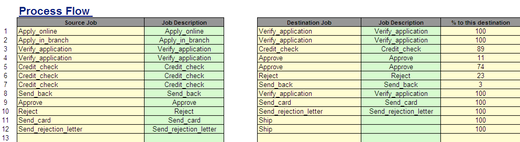
(Case information: 이 데이터는 모델에 작업의 입력값을 제공하기 위해 이용된다.)

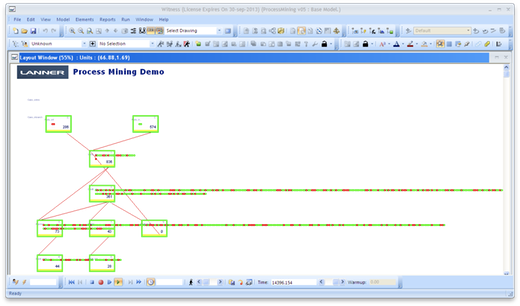
(Simulation: 시뮬레이션 모델은 엑셀 데이터에서 자동적으로 생성된다. 이 모델은 Disco와 유사한 ‘layout’을 포함한다.
이 모델은 Witness에서 작동되어 이 시스템을 통한 케이스들의 흐름을 보여주고,
이런 과정에서 성과관련 통계 자료를 수집한다.)
(Results: 결과들은 엑셀로 내보내지고, 각 활동이 발생한 빈도와 처리 시간 등을 포함한다.)
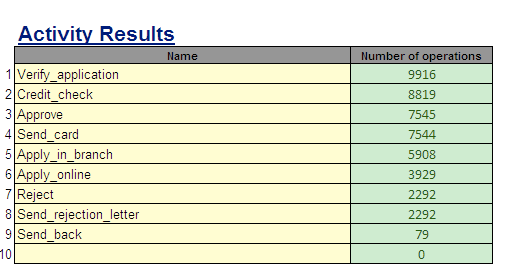
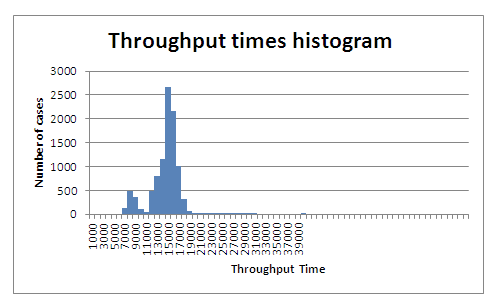
이 시뮬레이션 결과로부터 우리는 현재 프로세스가 시뮬레이션 모델에 의해서 정확하게 포착되었는가를 알 수 있다. 예를 들어, Witness에서 시뮬레이션 수행에서 생성된 처리 시간 히스토그램과 위에서 제시된 Disco의 케이스 시간의 통계치를 비교한다면 유사한 형태의 확률 분포를 확인할 수 있다.
그러나 이것이 명확하지 않음을 주목하자. 왜냐하면 시뮬레이션은 실제 프로세스에 근사하는 매개변수(parameter)에 기초하기 때문이다. (그리고 시뮬레이션은 프로세스 마이닝 분석처럼 완벽한 인스턴스 데이터에 기초해서 수행되지 않기 때문이다.)
단계 3: What-if 시나리오들을 탐색하기
좋은 시뮬레이션 모델을 가지고 있기 때문에 우리는 “what-if” 시나리오들을 탐색하는 것을 시작할 수 있다. 프로세스 마이닝 분석을 하는 동안 프로세스에서 신용 체크(credit check) 단계 전에 병목이 있음을 확인했다. 그러므로, 예를 들어, 만약 자원들을 검증(verification) 단계에서 신용 체크 단계로 옮긴다면 병목이 해결되고 고객들은 5일 이내에 그들의 신용카드를 받을 수 있을까?
시뮬레이션 모델의 매개변수(parameters)들과 구조를 바꿈으로써 다음과 같은 “what-if” 프로세스 개선 시나리오들이 전체 프로세스에 주는 영향을 탐구할 수 있었다.
- 만약 이 활동을 제거한다고 가정한다면?
- 만약 이 활동의 처리 시간을 줄인다면?
- 만약 30% 대신에 70%의 케이스들이 STP(Straight Through Processing) 경로를 따른다면?
- 만약 프로세스의 이 부분에서의 지연과 대기를 줄일 수 있다면?
- 만약 이러한 활동들을 하나의 단계로 합쳐서 동일한 사람이 수행한다면?
- 만약 이러한 두 개의 활동들이 순차적인 것보다는 병렬로 수행된다면?
- …
이와 같이 끊임없는 시나리오들이 있을 수 있다. 대안이 될 수 있는 이러한 프로세스 개선 시나리오들의 효과를 추정하는 것의 가치는 엄청나다. 왜냐하면 이러한 시나리오들 중의 하나를 실현하기 위해서 엄청난 돈을 투자하기 전에 대안이 되는 시나리오들의 효과를 사전에 검증할 수 있기 때문이다.
여러분의 피드백
우리가 포함한 매개변수가 현재로서는 단순 시뮬레이션 시나리오만을 가능하게 한다는 것이 분명하다. 예를 들어, 시뮬레이션 모델은 심지어 사람들을 고려하지 않고 있다. 시뮬레이션의 유용성은 시뮬레이션 모델의 품질에 좌우된다. 나는 ‘making simulation useful’에 관한 Bruce Silver가 쓴 기사들을 읽기를 제안하다. 그는 대부분의 BPM 도구들에서 시뮬레이션이 왜 가짜 기능(fake feature)에 그치는가를 설명하고 있다.
사실, 좋은 시뮬레이션 모델을 만드는 것에는 적어도 두 개의 측면이 있다.
- 다양한 프로세스 매개변수들을 모델링할 수 있는 시뮬레이션 도구의 역량 : 이것은 Bruce가 그의 비판에서 언급하고 있는 것이다. 그러나 대부분의 성숙되고 전문화된 시뮬레이션 도구들은 사실 여러분들이 필요로 하는 모든 기능들을 제공하고 있다.
- 직면한 문제에 대한 시뮬레이션 모델 자체의 적합성 : 이것은 종종 말하는 것보다 어렵다. 전체 세계를 시뮬레이션 모델에 담는 것은 타당하지 않다. 대신에 여러분은 가능한 한 간소하게 시뮬레이션 모델에 직면한 문제에 대한 적절한 매개변수들을 포착하고 싶을 것이다.
두 번째 측면을 다루기 위해서 우리는 시뮬레이션을 통해서 여러분이 답하고자 하는 질문들의 유형에 매우 궁금해할 수 있을 것이다. 목표가 무엇일까? 작업량을 다루는 것에 관한 것인가? 처리시간을 줄이는 것에 관한 것인가? 자원 가용성의 최적화에 관한 것인가? 다른 질문들이 있는가?
여러분이 과거에 시뮬레이션을 가지고 작업한 경험이 있는가? 프로세스 마이닝과 시뮬레이션을 함께 사용하고 싶은가?
Fluxicon제공 | PMIG 번역 ( e-mail: info@pmig.co.kr website: http://www.pmig.co.kr/ )