

린 6시그마와 프로세스 마이닝의 결합_분석
- 작성일2022/11/04 14:08
- 조회 3,166
Part 3. 분석 (Analyze) 단계
여기(클릭)에서 시리즈에 있는 모든 기사의 개요를 볼 수 있습니다.
앞선 CTQ 측정에서, 이미 프로세스의 목표(고객센터의 CTQ 1과 신용대출부서의 CTQ 2)가 충족되지 않았음을 확인했습니다. 다음 질문은 '잠재적인 원인이 무엇인가?' 입니다.
여러분은 고객센터가 최근 긴 디지털화 프로젝트를 완료했다는 것을 알고 있습니다. 그 프로젝트는 고객센터의 많은 리소스를 소비했습니다. 따라서 지금은 다른 프로젝트와 함께 첫 번째 CTQ에 들어가기에 가장 좋은 시기가 아니라고 결정합니다. 그러나 신용 관리자는 대출심사 프로세스에 대한 심층 분석에 매우 관심이 있습니다. 프로젝트 팀이 선정되고 첫 번째 회의가 예정되어 있습니다.
이 회의에서 측정값 및 관찰한 내용을 팀과 공유하고 지연의 잠재적 원인이 무엇인지 질문합니다. 세가지 가설을 설정하고 가설을 검증합니다. 불완전 케이스를 제거하고 기준을 달력일에서 근무일로 변경한 데이터를 기반으로 분석을 수행합니다.
가설 1 : 3 더 많은 대출심사자(underwriters)가 필요할 것이다.
첫번째 가설은 대출 심사팀이 감당할 수 있는 것보다 더 많은 작업이 들어오고 있다는 것입니다. 그렇다면, 시간이 지남에 따라 진행중인 작업이 쌓이는 결과가 초래되어야 합니다. 그러나 Disco의 Active cases over time 그래프를 보면, 진행 중인 작업이 계속 증가하고 있다는 증거를 찾을 수 없습니다(<그림 22> 참고).
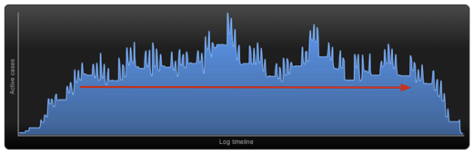
<그림 22> 진행 중인 작업이 시간이 지남에 따라 증가하는 추세를 보이지 않음
'Active cases over time' 그래프에서는 항상 시작에 'warm-up' 기간이 표시되고, 끝에는 'cool-down' 기간이 표시됩니다. 기간의 시작과 끝의 활성 케이스(active cases) 수는 0입니다. 물론 실제로 진행중인 케이스가 0건은 아니지만, 특정 시간대 이전에 활성화된 케이스는 데이터에 보이지 않습니다.
따라서 warm-up 종료와 cool-down 시작 사이에 해당하는 기간의 추세를 확인합니다(<그림22>의 빨간색 화살표 참고). 신용 대출 프로세스에서 진행 중인 작업이 크게 늘지 않았음을 알 수 있습니다.
가설 2 : € 50 이상의 대출 신청은 처리시간이 더 길 것이다.
연구팀은 또 높은 금액의 신용대출 신청이 더 복잡할 것으로 예상했습니다. 선임 대출심사자의 승인을 필요로 하기 때문에 대출심사자가 부재할 때 지연을 유발할 수 있습니다.
먼저 Disco의 'Amount' 속성을 기반으로 케이스를 필터링하여 최대 €50,000 의 금액을 가진 모집단(A)와 €50,000 이상의 금액을 가진 모집단(B)로 대출신청 케이스를 분할해 해당 가설을 검증합니다. 모집단 (B)의 대출신청에 대한 평균 및 중앙값의 대출신청 처리기간은 모집단(A) 보다 약간 더 길게 나타났습니다. 그러나 이러한 차이가 통계적으로 유의한지 확인해야 합니다.
Disco에서 케이스 내보내기(export)를 통해 각 모집단의 케이스 리드타임을 추출할 수 있습니다. Minitab에서 이 두 모집단을 대상으로 가설 검증을 수행하여 모집단(A)와 (B)의 리드 타임 평균이 실제로 다른지 확인하고자 합니다. 두 모집단의 케이스 수행기간을 시간(근무시간 기준)으로 변환하고 하나의 파일에서 별도의 열로 복사합니다(<그림23> 참고).
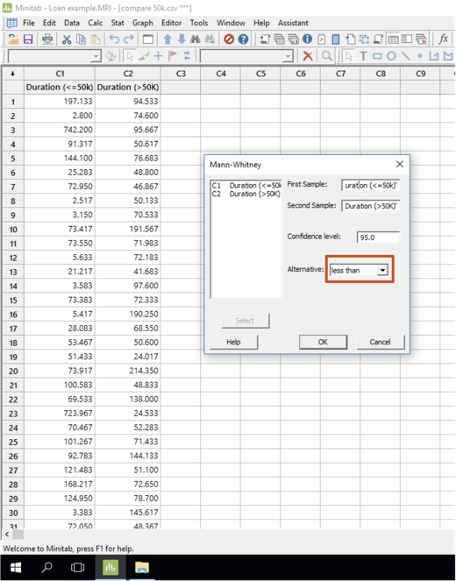
<그림 23> Minitab에서 Mann-Whitney 검정
여기서 고려해야 할 한가지 중요한 점은 신용대출 프로세스의 케이스 기간 분포가 정규 분포를 따르지 않는다는 것입니다. 예측 가능한 기계가 아닌 사람이 중심 역할을 하는 대부분의 서비스 프로세스에서 이러한 결과가 나타납니다. 결과적으로 정규 분포를 가정하는 가설 검정(예: ANOVA 검정)은 적합하지 않습니다. 대신 Mann-Whitney와 같은 비모수 검정을 사용합니다. <그림 23>은 최대 €50,000의 대출 신청이 €50,000 이상의 대출신청보다 처리시간이 더 적게 걸린다는 가설이 사실인지 Mann-Whitney 검정 결과를 보여줍니다.

<그림 24> Minitab의 가설검증 결과에 따르면 €50,000 이상의 신용대출 신청에 훨씬 더 많은 처리시간이 필요하지 않았습니다.
<그림 24>는 Minitab의 Mann-Whitney 가설 검정 결과를 보여줍니다. 두 모집단에 유의한 차이가 있는 경우 p- 값이 0.05보다 작아야 합니다. 그러나 <그림 24<의 결과에서는 p-값인 0.113이 0.05보다 크므로 €50,000 이상의 금액에 대한 신용 대출신청 처리에 훨씬 더 많은 시간이 걸리지 않는다는 결론을 내릴 수 있습니다.
가설 3 : 불완전 케이스 처리에 더 많은 시간이 소요될 것이다.
앞서 CTQ 측정 단계에서 일부 대출신청이 고객의 요청에 따라 의도적으로 지불을 지연시키기 위해 '불완전(Incomplete)'상태로 설정되었음을 알게 되었습니다. 그러나 이는 실제로 불완전한 대출신청이 아니기 때문에 해당 케이스를 기준 데이터 셋에서 제외했습니다. 이러한 데이터 품질 문제를 수정한 후에도 신용대출 신청이 한 번 이상 완료되지 않은 경우가 여전히 2,339건(기준 데이터 셋의 53%차지)에 달하고, 그 중 일부는 이러한 문제가 여러 번 반복되는 것을 확인하였습니다.
세번째 가설을 이러한 불완전한 대출 신청 건 처리에 더 많은 시간이 소요된다는 것입니다. 결국 누락된 정보는 이메일로 요청해서 고객으로부터 다시 받아야 합니다. 따라서 이는 3 영업일 이내에 고객에게 대출에 대한 확신을 주겠다는 약속이 실현될 수 없는 이유 중 하나일 수 있습니다.
가설 3 검증을 위해 데이터를 2개의 모집단으로 다시 분할합니다. (A)즉시 완료 (never incomplete)된 대출신청 케이스, (B)한번 이상의 불완전(Incomplete)단계가 포함된 대출신청 케이스
Disco 프로세스 맵에서 'Incomplete' 액티비티를 클릭하면 나타나는 'Filter this activity...' 바로 가기를 사용하여 사전 구성된 Attribute 필터에서 'Mandatory' 모드 (모집단 B)를 지정하여 데이터를 쉽게 분할할 수 있습니다. 불완전한 단계가 포함된 대출신청 케이스는 Attribute 필터에서 'Forbidden' 모드(모집단 A)를 지정하여 필터링할 수 있습니다. 이 두가지 모드는 'Incomplete' 액티비티 수행 유무를 기준으로 데이터를 필터링합니다.
모집단 A(왼쪽)와 B(오른쪽)의 프로세스 맵은 아리 <그림 25>에 제시되어 있습니다.
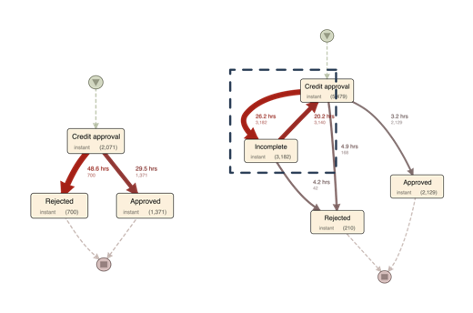
<그림 25> 한 번에 완료된 대출신청 케이스(모집단 A, 왼쪽)와 한번 이상의 불완전(Incomplete)단계가 포함된 대출신청(모집단 B, 오른쪽)의 프로세스 맵 (기간 중앙값을 기본 측정항목으로, 절대 빈도를 보조 측정항목으로 사용)
프로세스 맵을 통해, 고객에게 누락된 정보를 요청할 때마다 중앙값 기준으로 26.2 + 20.2 시간이 추가로 누적된다는 것을 알 수 있습니다. 모집단 A는 중앙값 기준으로 1.9 영업일의 리드타임을 가지며, 모집단 B의 경우 중앙값 기준 3.2 영업일의 리드타임을 가집니다. 이제, 이 차이가 통계적으로 유의한지 확인해야 합니다.
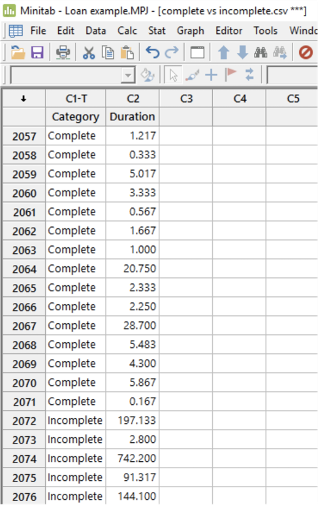
<그림 26> Minitab에서 영업일 기준 완료된(Complete) 대출신청 건(모집단 A)과 불완전(Incomplete) 대출신청(모집단 B) 케이스의 수행 기간(근무시간 기준)
Disco에서 모집단 A와 B에 속한 각각의 케이스 수행기간을 내보낸 다음, 모집단 A의 범주 레이블은 'Complete'으로, 모집단 B의 범주 레이블은 'Incomplete'으로 지정하여 Minitab으로 복사합니다(<그림26> 참고). 그런 다음, Minitab에서 Graphical Summary analysis를 수행하여 데이터에 대한 통계 개요 정보를 얻습니다. <그림 27>은 결과 요약을 보여주며, 이전과 마찬가지로 데이터가 정규분포를 따르지 않음을 확인할 수 있습니다(오른쪽 하단 모서리의 빨간색 강조 표시 참고).
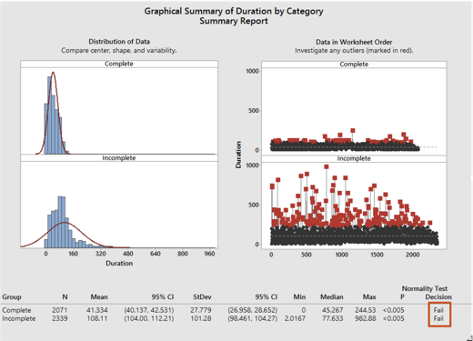
<그림 27> 모집단 A와 B에 대한 Minitab의 Graphical Summary analysis 수행결과. 두 모집단 모두 정규 분포를 따르지 않는 것으로 나타남
가설 2에서와 마찬가지로 Mann-Whitney 가설 검정을 다시 적용합니다.
그러나 이번에는 결과를 통해 두 모집단의 케이스 수행기간이 유의하게 다르다는 것을 알 수 있습니다(<그림28> 참고). p-값이 0 이므로 0.05보다 작습니다. 따라서 가설 3이 '참'임을 확인할 수 있습니다. 결과는 95% 신뢰도에서 불완전한 대출신청이 한 번에 완료된 대출 신청보다 44.7~47.4 시간 더 오래 걸린다는 것을 보여줍니다.
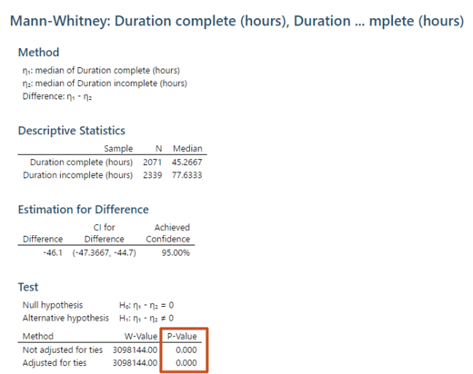
<그림 28> Minitab의 가설 검정 결과에 따르면 불완전한 대출신청은 한번에 완료된 대출신청에 비해 상당히 많은 시간이 소요됨
근본 원인에 대한 심층 분석 (20)
프로세스 맵에서 대출신청의 불완전한 빈도를 확인할 수 있지만 동일 케이스 내에서 '불완전' 루프가 얼마나 자주 반복되는지는 알 수 없습니다. 해당 정보는 간단한 데이터 처리 작업을 통해 확인할 수 있습니다. 또는 각 반복을 프로세스 맵에서 개별 액티비티로 열거하여 루프를 펼치는 것도 도움이 될 수 있습니다.
<그림29>는 펼쳐진 루프가 있는 완전한 대출신청과 불완전한 단계가 포함된 대출신청 모두에 대한 프로세스를 보여줍니다. 액티비티 이름 뒤의 숫자는 1번째, 2번째, 3번째, 4번째, 5번째 또는 6번째 대출신청('불완전' 루프의 수행 횟수)을 나타냅니다. 대부분의 경우, 반복을 펼치면 대출심사팀이 최종 결정을 내리기 전에 한번의 추가 요청만 하면 된다는 것을 알 수 있습니다. 그러나 하나의 케이스에서 최종 승인까지 6번의 반복이 수행되었고, 또한 추가 정보에 대한 5번째 요청 이후에 거절된 대출신청이 없었음을 알 수 있습니다.
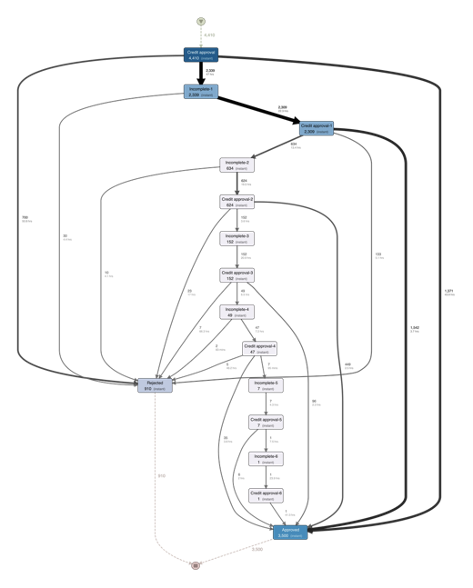
<그림 29> 루프가 전개된 신용대출 신청 프로세스의 흐름
이와 같이 전개된 프로세스 맵은 이미 진행 중인 상황에 대한 더 깊은 통찰력을 제공하지만 여전히 "왜 이 케이스들이 불완전할까?" 라는 질문에 답하지 못합니다. 대출신청이 완료되지 않은 이유가 데이터에 기록되지 않았기 때문에 초기 데이터 셋을 기준으로 해당 질문에 답할 수 없습니다. 대출심사자와 상의한 후에 여러분은 필요한 서류가 고객마다 다르다는 것을 이해합니다. 처음에는 간단해 보이지만 특히 여러 소득원(고용 상태, 연금 등)을 평가해야 하는 경우, 서류 요건은 매우 빠르게 복잡해질 수 있습니다.
대출심사 정책의 그레이 존에 해당하는 케이스는 대출심사자가 해석할 여지를 남겨둡니다.
다행히도 '불완전한' 이유를 이메일 데이터에서 확인할 수 있습니다. 이메일 데이터는 비정형 데이터이기 때문에 기존 데이터 셋을 보강하려면 수동으로 검토해야 합니다. 전체 데이터 셋의 모든 대출신청에 대한 '불완전한' 이유를 얻으려면 상당한 노력이 필요합니다. 따라서 이러한 불완전한 대출 신청에서 자주 누락되는 것이 무엇인지 이해하기 위해 샘플을 추출하기로 결정했습니다. 샘플 데이터는 총 177건의 대출신청에 대해 939 개의 불완전한 문서를 설명합니다. Minitab에서 파레토(Pareto) 분석을 수행하여 누락된 문서의 빈도를 표시할 수 있습니다(<그림30> 참고).
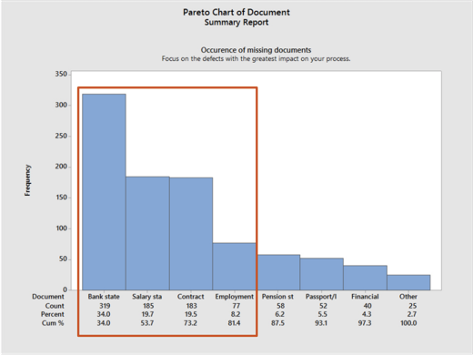
<그림 30> '불완전한' 이유에 대한 파레토 분석 결과
Disco에서 파레토 보기를 생성할 수도 있습니다. 또한 원본 데이터에서 해당 '불완전' 액티비티에 '불완전 사유'속성을 추가하면 추가적인 분석 가능성을 얻을 수 있습니다. 예를 들어, 다양한 '불완전 사유' 속성 조합을 기준으로 필터링하여 이러한 하위 집합에 대한 프로세스 맵을 보다 자세히 볼 수 있습니다.
<그림 30>의 '불완전한' 이유에 대한 파레토 분석 결과를 통해 은행 거래 명세서가 가장 빈번한 문제임을 알 수 있습니다. 급여명세서, 계약서상의 문제(예: 서명 누락), 고용명세서 등과 함께 불완전한 문서의 81.4%가 발생합니다. 이러한 '불완전한' 원인을 해결하는데 집중하는 것이 좋은 시작이 될 수 있습니다.
이러한 '불완전' 이유에 대한 근본 원인을 찾으려면 보다 자세한 분석이 필요합니다. 예를 들어, 문서가 누락되었을 수 있습니다. 그러나 문서를 읽을 수 없거나 (잘못된 사진 또는 스캔), 형식이 잘못되었거나, 법적으로 유효하지 않을 수도 있습니다. 근본 원인으로 무엇이 잘못되었고, 이것을 미래에 어떻게 예방할 수 있는지 이해하는 것이 핵심입니다. Fishbone 다이어그램 또는 5-Times-Why 와 같은 고전적인 린 6 시그마 도구는 데이터가 알려줄 수 있는 한계에 도달했을 때 효과적입니다.