

프로세스 마이닝에서 불완전한 케이스를 처리하는 방법
- 작성일2021/12/29 15:45
- 조회 1,483
프로세스 마이닝 분석을 시작하기 전에 여러분은 데이터 품질 문제를 검증할 필요가 있다(프로세스 마이닝을 통한 데이터 품질 체크리스트 아티클). 그런 다음에 여러분은 데이터에 포함된 완전 케이스(complete cases)와 불완전 케이스(incomplete cases)를 구별하는 방법을 이해해야 한다. 이러한 구별은 프로세스 마이닝 분석의 결과에 매우 중요한 영향을 준다. 불완전 케이스는 프로세스의 시작 또는 종료 액티비티가 빠진 케이스를 말한다.
불완전 케이스가 발생하는 몇 가지 이유가 있다.
- 특정 기간에 발생한 이벤트만을 포함하는 데이터 추출 방식을 채택한 경우에 불완전 케이스가 발생할 수 있다. 예를 들어, 특정 연도에 수행된 프로세스 단계(즉, 액티비티)들에 관한 데이터를 추출했다고 가정하자. 일부 케이스는 해당 연도 전에 시작했을 수도 있다. 이 경우의 케이스는 시작 액티비티가 빠진 불완전 케이스가 된다. 또 다른 케이스는 해당 연도에 시작되었으나, 다음 연도까지 수행해야 할 수도 있다. 이 경우의 케이스는 종료되지 않은 불완전 케이스가 된다.
- 현재 시점까지 기록된 모든 데이터를 추출한다고 해도 최근에 시작되어 아직 완료되지 않은 일부 케이스가 포함될 수 있다. 몇 주 기다린 다음에 데이터를 추출한다면 이러한 케이스가 완료될 수도 있을 것이다. 그러나 기다린 기간 동안에 새롭게 시작된 케이스는 또 다른 불완전 케이스가 될 수 있다!
- 놀랍게도 결코 완료되지 않는 일부 케이스가 있을 수 있다. 여러분은 분석 대상 프로세스의 바람직한 수행에 관한 명확한 모습을 가질 수 있다. 그러나 현실에서는 프로세스가 완료되지 않는 예외적인 상황이 발생할 수도 있다. 예를 들어, 기대와 다르게, 고객이 다시 연락하지 않을 수도 있다. 공급업체가 계약에 필요한 정보를 보내지 않을 수도 있다. 또는 오류가 있거나 다른 문제가 발견되어 동료가 예상하지 않은 단계에서 케이스를 종료할 수도 있다. 여러분이 오랫동안 기다린다고 해도 이러한 케이스들은 결코 종료되지 않을 것이다. 시작점에 대해서도 동일한 내용이 적용될 수 있다.
프로세스 마이닝 분석을 본격적으로 시작하기 전에 불완전한 케이스를 찾는 것은 항상 수행해야 할 필수 단계이다. 이 아티클은 불완전한 케이스를 발견하고 처리하기 위한 가이드라인을 설명할 것이다. 이러한 가이드라인은 실무 프로세스 마이닝 분석의 수행에 큰 도움이 될 것이다.
1. 불완전 케이스는 왜 문제가 될까?
언뜻 보기에는 불완전 케이스가 문제가 되는 이유가 명확하지 않을 수도 있다. 프로세스 마이닝 분석은 실제 발생했던 것을 보여주어야 하므로 여러분은 추출된 데이터에 기록된 것을 그대로 보여주는 것이 타당하다고 주장할 수도 있다.
그러나 적어도 불완전 케이스에 관한 한 이러한 주장은 잘못된 것이다: 만약 여러분의 데이터가 (첫 페이지에 언급된) 1번과 2번의 이유로 불완전 케이스를 포함하고 있다면 시작과 종료 지점이 빠진 케이스가 실제 프로세스를 반영하는 것이 아니다. 왜냐하면 이러한 케이스는 데이터가 추출되는 방식 때문에 발생한 것이기 때문이다.
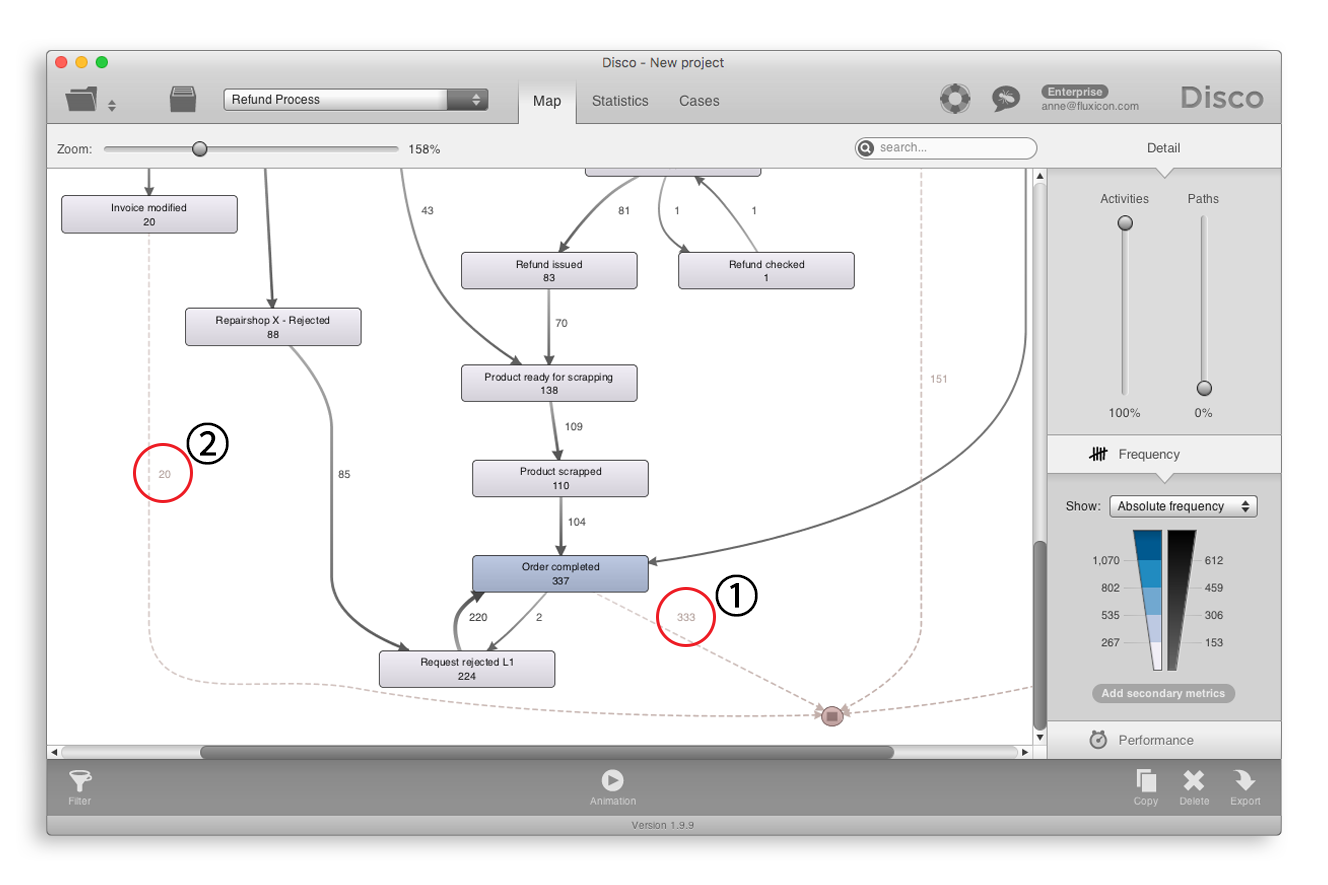
[그림1] 반품 프로세스의 일부
[그림 1]은 반품 프로세스의 일부를 나타내고 있다. 종료 지점(프로세스 맵의 가장 하단에 있는 사각형 기호)을 향하는 점선들은 어떤 액티비티들이 마지막 단계로 실행되었는가를 나타내고 있다. 예를 들어, 333개의 케이스에 대해 ‘Order completed’ 액티비티가 가장 마지막 단계로 기록되어 있다([그림 1]의 ① 참조). 이 액티비티는 해당 프로세스의 그럴듯한 종료 지점이 될 수 있다. 그러나 ‘Invoice modified’가 종료 액티비티인 20개의 케이스가 있다([그림 1]의 ② 참조). 이 액티비티는 해당 프로세스의 실제 종료 단계로는 적절하지 않다고 판단될 것이다.
‘Invoice modified’로 종료된 예제 케이스를 살펴보면 ‘Invoice modified’ 단계가 실제로 전체 데이터셋의 종료 직전에 발생했음을 알 수 있다. 예를 들어, ‘Case515’의 ‘Invoice modified’ 단계는 2012년 1월 20일에 발생했고, 전체 데이터셋은 2012년 1월 23일에 종료되었다. 만약 우리가 2012년 6월까지 기록된 데이터를 가지고 있다면 ‘Invoice modified’ 이후에 발생한 다른 단계들에 대한 기록이 이 데이터에 포함되어 있을 것이다.
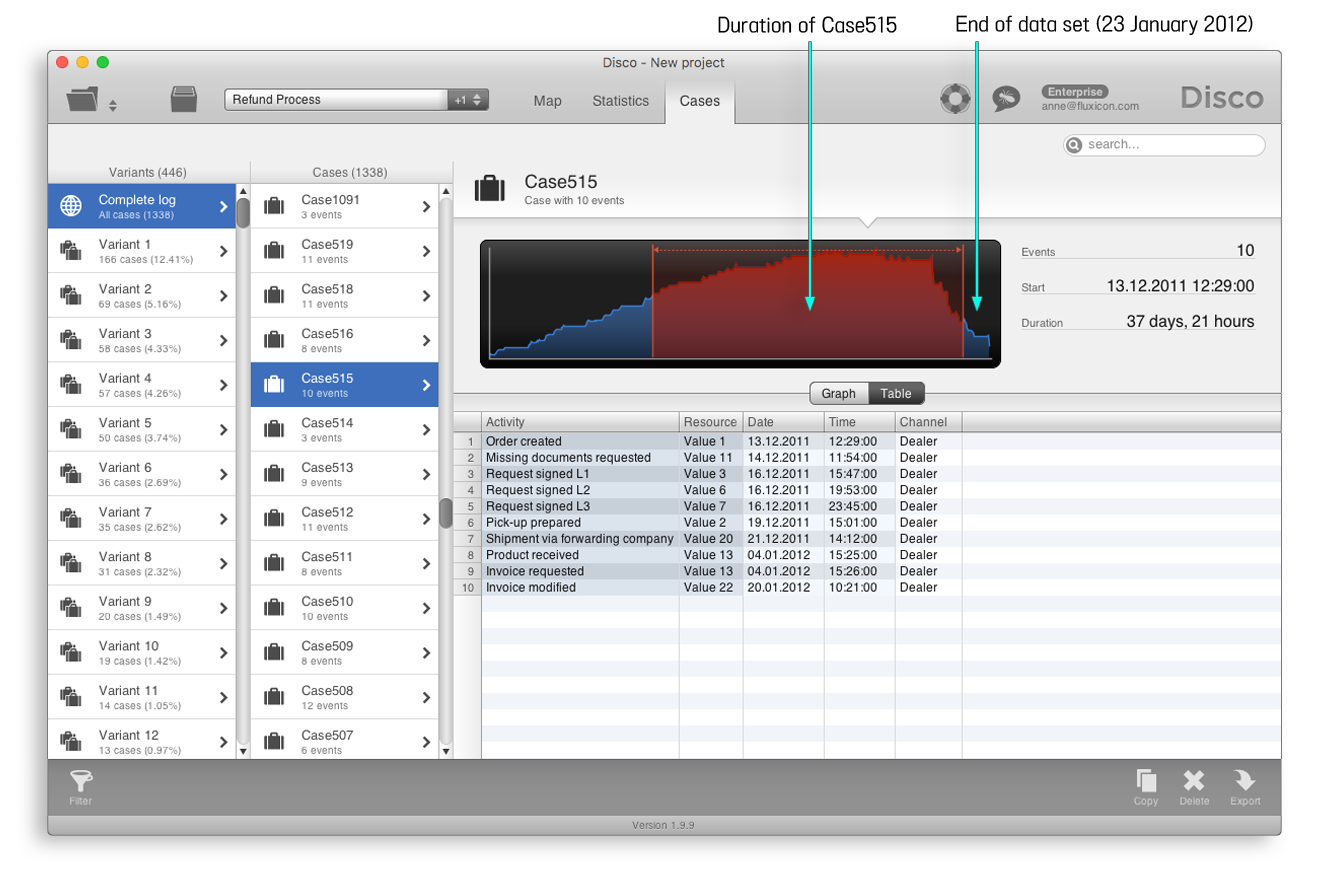
[그림 2] ‘Invoice modified’ 액티비티로 종료된 예제 케이스들
그러므로 우리는 ‘데이터에 포함된 모든 종료 단계들이 반드시 분석 대상 프로세스의 의미 있는 종료 단계가 되는 것은 아님’을 알 수 있다. 앞에서 언급한 것처럼, 실제 발생했던 시작과 종료 단계가 빠지거나 데이터 추출 방식으로 불완전 케이스가 발생할 수 있다. 또는 실제로 수행이 멈춘 케이스가 불완전 케이스가 될 수 있다. 이러한 불완전 케이스를 포함하는 데이터셋에 대한 프로세스 맵이나 베리언트를 살펴볼 때 해당 맵과 베리언트는 분석 대상 프로세스의 실제 시작과 종료 단계를 보여주는 것이 아니라, 데이터에 포함된 시작과 종료 단계를 보여주는 것임을 명심해야 한다.
불완전 케이스와 관련된 또 다른 문제는 케이스 수행기간(case duration)이 오도될 수 있다는 것이다. 프로세스 마이닝 도구는 정상적으로 완료된 케이스와 불완전 케이스를 구별하지 못한다. 그러므로 프로세스 마이닝 도구는 로딩된 데이터셋에 포함된 모든 케이스의 시작 이벤트와 최종 완료 이벤트 간의 시간 간격을 케이스 수행기간으로 계산한다.
결론적으로, 불완전 케이스의 수행기간은 정상 완료된 케이스의 수행기간보다 프로세스 마이닝 도구에서 짧게 나타난다. [그림 3]에 나타난 예시 케이스(즉, ‘Case72’)가 이러한 상황을 잘 나타내고 있다. 두 개의 단계(‘Order created’와 ‘Missing documents requested’)로 구성된 ‘Case72’의 수행기간은 단지 3분에 불과하다.
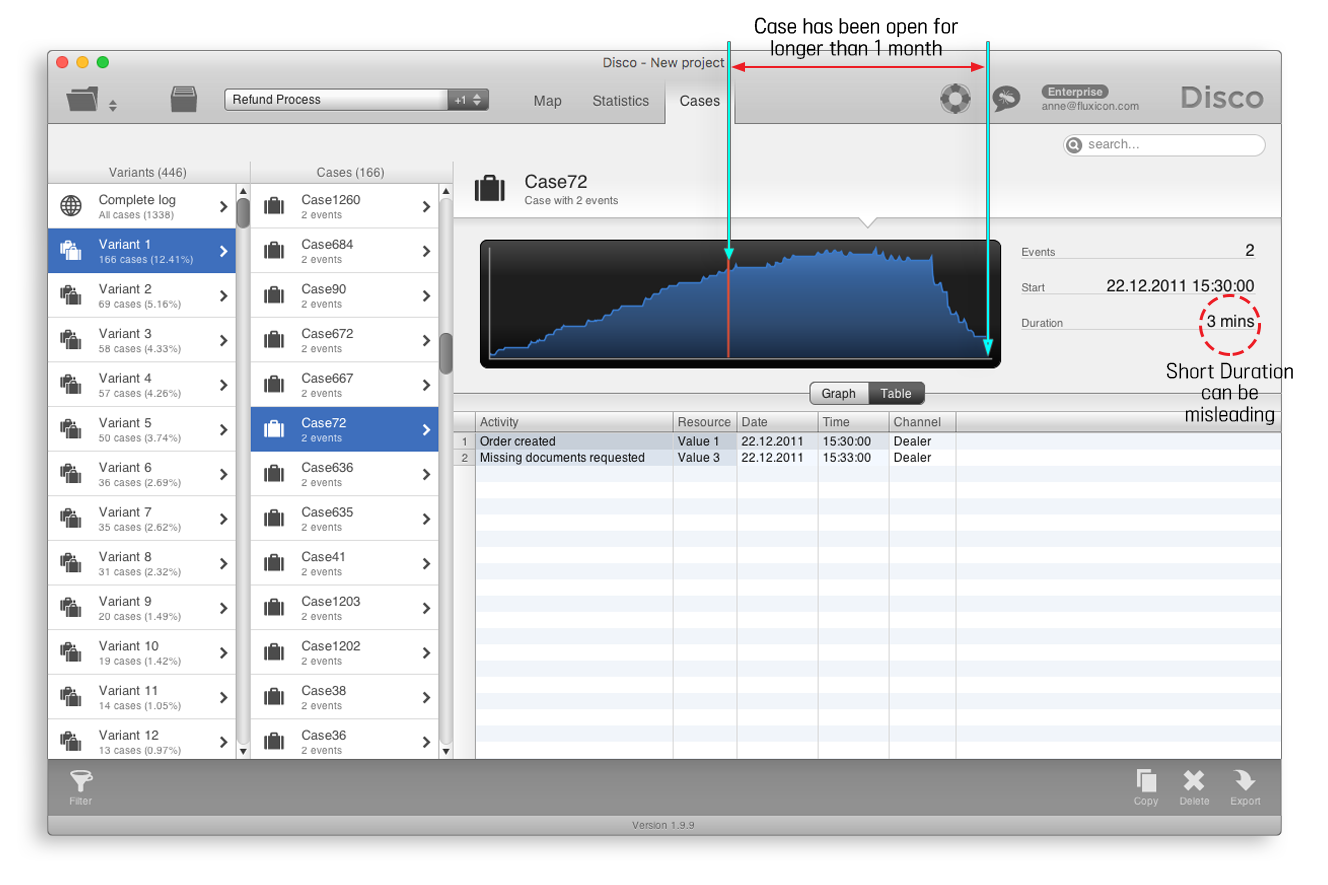
[그림 3] 2개의 단계로 구성된 ‘Case72’의 수행기간
‘Missing documents requested’ 단계는 해당 프로세스의 실제적인 종료 단계가 아니다. 왜냐하면 이 단계는 고객에게 요청한 추가 문서(예, 구매 영수증)를 기다리는 중간 상태이기 때문이다. [그림 3]에 나타난 것처럼, 이 단계가 수행된 이후로 이 케이스는 1달 이상 미완료(open) 상태로 있었다. 그러므로 이 케이스의 실제 수행기간은 적어도 1달과 3분 이상이어야만 한다.
프로세스 마이닝 분석을 수행할 때 불완전 케이스를 제거하지 않는다면 통계 뷰의 평균(또는 중간) 케이스 수행기간과 같은 계산이 불완전 케이스에 의해 영향을 받는다. 이와 같이, 불완전 케이스는 프로세스 맵과 베리언트 도출에 영향을 줄뿐만 아니라, 시간 관점의 지표 값 도출에도 영향을 준다.
그러므로 여러분은 실제 분석을 시작하기 전에 여러분의 데이터에 포함된 불완전 케이스를 조사할 필요가 있다. 또한 여러분은 어떤 종류의 불완전 케이스가 얼마나 많이 존재하는가를 이해할 필요가 있다. 그런 다음에 대상 프로세스를 자세하게 분석하기 전에 여러분은 데이터셋에서 이들을 제거할 필요가 있다. 우리는 Disco에서 이러한 작업을 수행하는 방법을 이 아티클의 나머지 부분에서 설명할 것이다.
마지막으로, 일부 데이터셋은 불완전 케이스가 존재하지 않는 방식으로 추출될 수도 있다. 예를 들어, 여러분은 IT부서로부터 반품 프로세스의 종결된(closed) 케이스만을 포함하는 데이터셋만을 받을 수도 있다. 그러므로 미완료된 어떤 반품 주문(즉, 불완전 케이스)도 여러분의 데이터에 나타나지 않을 것이다.
이 경우에 더 이상 불완전 케이스를 제거할 필요가 없으나, 여러분은 케이스의 전체 모집단 대비 여러분의 데이터셋에 포함된 케이스들이 얼마나 대표성을 갖는가를 명확히 파악할 수도 없다. 사실, 불완전 케이스를 제거한 이후에 얼마나 많은 케이스가 남는가를 파악하는 것은 매우 중요한 작업이다. 불완전 케이스가 포함되지 않도록 데이터를 추출하는 방식이 가지는 이러한 한계를 이해하고, 제공된 데이터셋과 동일한 기간 동안 발생한 미완료 케이스를 포함하는 데이터셋에 대한 요청을 고려하라. 두 개의 데이터셋을 동시에 파악함으로써 여러분은 대상 프로세스에 대한 전체 모습을 파악할 수 있을 것이다.
2. 분석 대상 프로세스의 시작과 종료 지점을 결정하는 방법
불완전 케이스의 식별을 위한 데이터셋 분석을 시작한다면 여러분은 분석 대상 프로세스의 예상되는 시작과 종료 단계를 결정할 필요가 있다. 이러한 결정을 위해 여러분은 프로세스에 관한 도메인 지식을 활용해야 한다. 프로세스 마이닝 분석을 수행하는 분석가가 해당 도메인 지식을 보유하고 있지 않다면 도메인 지식을 보유한 전문가를 이 단계에 참여시키는 것이 권장된다. 여러분은 프로세스 맵에서 파악된 잠재 시작과 종료 단계 중 타당한 시작과 종료 단계를 도메인 지식을 활용하여 결정해야 한다.
앞에서 언급한 반품 프로세스에서 우리는 ‘Order completed’ 액티비티라는 하나의 정규 종료 단계를 확인했다. 이외에도 다른 정규 종료 단계가 존재할까? 예를 들어, 데이터를 더욱 깊게 파고 들어감으로써 우리는 ‘Cancelled’라는 잠재 종료 액티비티를 발견했다. 우리는 이 액티비티의 이름에서 이 단계가 의미하는 것(즉, 반품 주문의 처리가 중단되었음)을 추측할 수 있다. 우리의 중요한 과제는 ‘Cancelled’ 액티비티를 이 프로세스의 정규 종료 단계로 간주할 것인지 아니면 이후의 프로세스 분석에서 이 단계로 끝나는 케이스들을 제거할 것인지를 결정하는 것이다.
이러한 결정은 여러분의 프로세스 마이닝 분석에서 답하고자 하는 질문들에 달려있다. 앞에서 언급한 것처럼, 여러분은 데이터에서 발견된 프로세스 종료 단계들을 어떻게 해석할 것인가를 명확히 판단할 수 있는 도메인 지식을 필요로 한다. 그러나 (도메인 지식이 부족한) 프로세스 분석가가 초기 추측을 하는 것도 괜찮다. 그러나 여러분은 반드시 추측과 가정을 문서화하여 나중에 도메인 전문가와 함께 이들을 검증해야만 한다.
어떤 액티비티들이 시작과 종료 지점을 위한 후보가 될 수 있는가를 전혀 알지 못할 때 여러분이 시도할 수 있는 2개의 팁이 있다.
1. 발견된 프로세스 맵에서 종료 지점으로 향하는 점선 중의 하나를 클릭하라([그림 4] 참조). 만약 케이스 빈도가 종료 빈도와 동일하다면(또는 매우 유사하다면) 이 액티비티가 분석 대상 프로세스의 종료 단계일 가능성이 높다. 왜냐하면 이 액티비티의 이후에 발생한 이벤트가 없기 때문이다. 시작 액티비티를 발견할 때도 시작 지점에서 시작한 점선을 클릭함으로써 동일한 방식을 적용할 수 있다.
특정 종료 단계로 끝나는 예시 케이스들을 더욱 자세하게 조사하기 위해 [그림 4]의 ‘Filter for this end activity...’를 클릭하고, 사전에 설정된 종점 필터(Endpoints filter)를 적용하라. 예시 케이스들을 검토한 이후에 해당 액티비티가 종료 지점으로 결정된다면 종료 지점으로 향하는 다른 점선들을 동일한 방식으로 조사하라.
반대로 만약 해당 액티비티가 종료 지점이 아니라면 종점 필터의 선택을 반전하고(예를 들어, [그림 4]에서 ‘Warehouse’가 종료 액티비티가 아니라면 종점 필터에서 선택된 ‘Warehouse’를 반전하여 선택을 해제하라), 이 액티비티로 끝나는 케이스들을 제거하기 위해서 반전된 필터 설정을 적용하라. 그런 다음에 남은 데이터셋에 대한 검토를 지속하고 프로세스 맵의 다음 점선을 클릭하라. 이러한 방식을 통해서 여러분은 정규 종료 단계가 아닌 액티비티들을 점진적으로 제거해 나갈 수 있다.
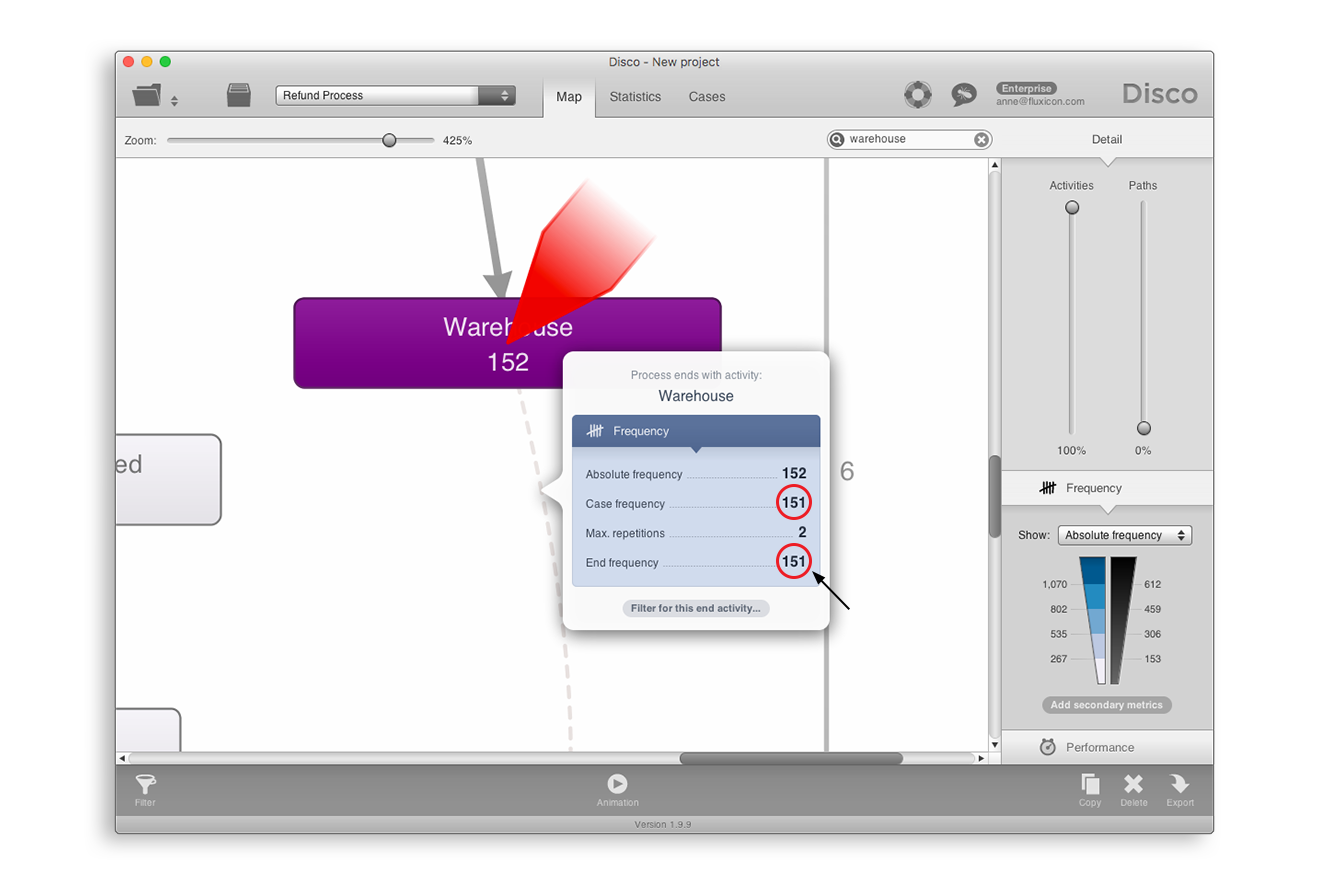
[그림 4] 종료 지점으로 향하는 점선의 확인
2. 케이스 수행기간에 비해 여러분의 데이터가 충분히 긴 기간을 포함할 때에만 두 번째 팁이 적용될 수 있다. 첫 번째 팁에서 설명된 대로 시작과 종료 지점들을 조사하기 전에 다음과 같은 방식으로 타임프레임 필터(Timeframe filter)를 적용해 보라.
- 프로세스의 종료 지점을 조사하기 위해, [그림 5]에 나타난 것처럼, 타임프레임 필터를 추가하여 전체 타임프레임의 첫 번째 반을 포함하라. 이 필터의 적용 결과, 전체 타임프레임의 두 번째 반 동안에 어떤 액티비티도 발생하지 않은 케이스들이 도출될 것이다. 그러므로 이 필터의 적용에서 도출된 프로세스 맵은 분석 대상 프로세스의 실제 종료 단계들을 나타낼 가능성이 높다. 한편, 이러한 타임프레임 필터는 데이터셋의 종료일 며칠 전에 수행되었던 중간 단계들을 종료 액티비티로 가지는 케이스들을 배제할 때도 활용될 수 있다.
- 프로세스의 시작 지점을 조사하기 위해 여러분은 유사한 방식을 따를 수 있다. 이 경우에 여러분은 전체 타임프레임의 후반부를 포함하는 방식으로 타임프레임 필터를 설정하라. 이러한 방식을 통해서 데이터셋의 시작일 직전에 시작된 불완전 케이스들이 배제될 수 있을 것이다.
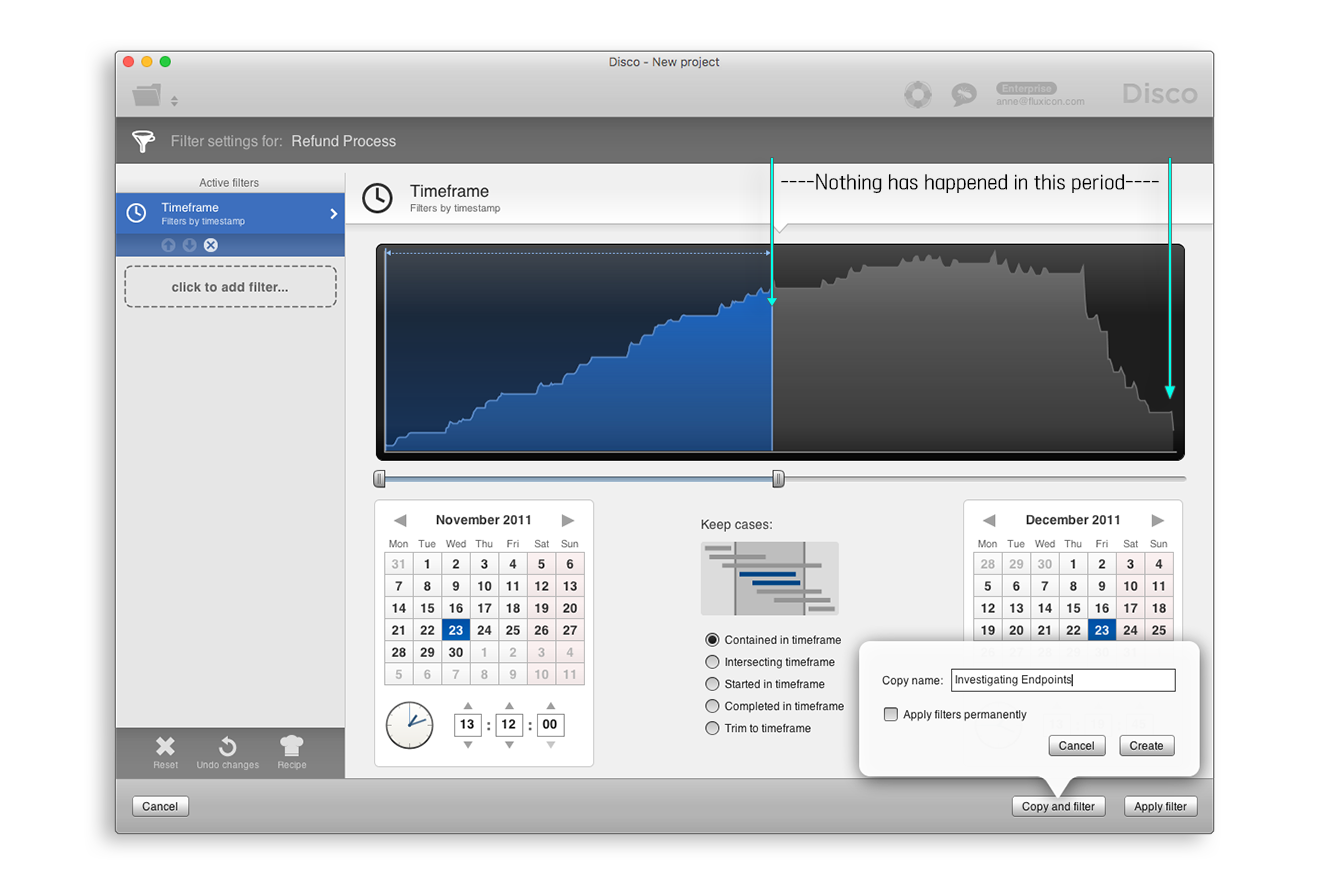
[그림 5] 타임프레임 필터의 적용
3. “완료됨(finished)”의 다양한 의미
시작과 종료 단계를 결정한 이후에 여러분은 여전히 대상 프로세스에서 “완료됨”이 실제로 의미하는 것에 대해서 생각할 필요가 있다. “완료됨”에 대한 다양한 해석이 가능하고 그 차이점들은 미묘할 수 있다. “완료됨”의 의미에 따라 여러분은 다양한 필터를 적용할 필요가 있다. 적용된 필터의 결과는 다양할 수 있다. 그러므로 여러분은 “완료됨”의 어떤 의미가 추출된 데이터셋에 적합한가를 명확히 할 필요가 있다.
“완료됨”의 의미에 따라 불완전 케이스를 필터링할 수 있는 4개의 예제가 제시될 것이다. 일반적으로 어떤 것이 더욱 좋고, 적당하다고 말할 수가 없다. 분석 대상 프로세스와 “완료됨”의 의미에 따라 여러분은 적절한 것을 선택하면 된다.
끝남(Ended In)
아마도 “완료됨”의 가장 일반적인 의미는 케이스에서 어떤 액티비티들이 (종료 지점에 대해) 가장 마지막 액티비티로 발생했는지 또는 (시작 지점에 대해) 가장 최초 액티비티로 발생했는지를 살펴보는 것이다. 가장 최초 또는 마지막 액티비티는 프로세스 맵에서 점선과 연결되어 있다. [그림 6]과 같이, 여러분은 ‘Discard cases’ 모드로 종점 필터를 적용해서 특정 액티비티들의 집합으로 시작되거나 끝난 모든 케이스들을 거를 수 있다.
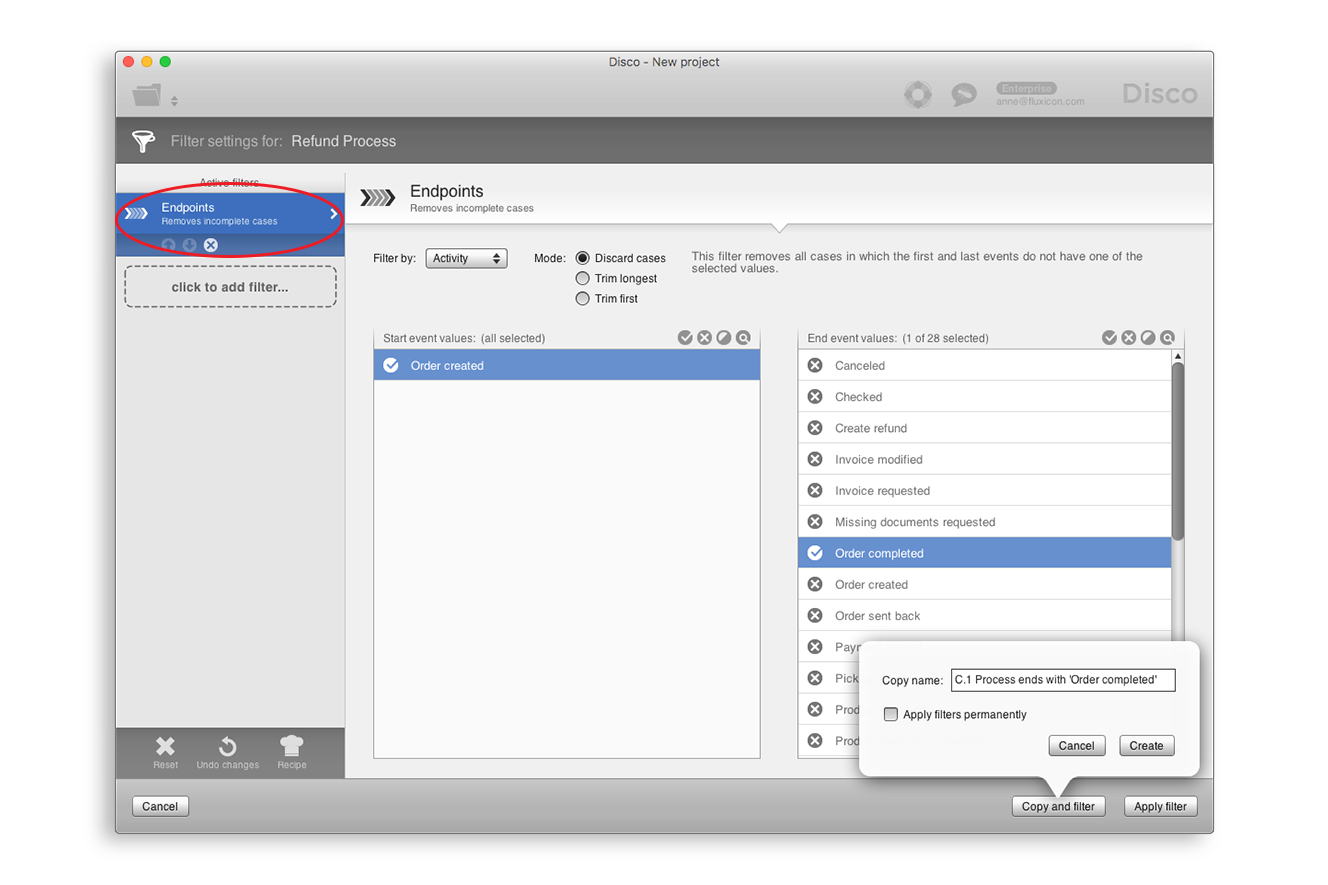
[그림 6] ‘Discard cases’ 모드로 종점 필터 적용하기
[그림 6]의 필터를 추가하면 ‘Order created’로 시작되어 ‘Order completed’로 완료된 케이스만이 선별되어 보여진다. [그림 6]과 같이, 반품 프로세스의 정규 종료 액티비티를 ‘Order completed’로 선정(반품 프로세스는 항상 ‘Order created’로 시작함)하여 종점 필터를 적용하면 여러분은 전체 1,338개의 케이스에 필터가 적용된 결과인 333개의 케이스를 얻게 된다.
만약 필터된 데이터셋을 추가 분석을 위한 새로운 참조(기본) 데이터셋으로 활용하고 싶다면 ‘Copy and filter’ 버튼을 누른 후에 ‘Apply filters permanently’ 체크박스를 선택하면 된다. ‘Apply filters permanently’ 체크박스를 선택하면 해당 필터가 영구적으로 적용되어 333개의 케이스를 포함하는 새로운 데이터셋이 만들어진다.
달성된 마일스톤(Reached Milestone)
때때로 케이스에서 발생된 최종 액티비티가 케이스의 완료 여부를 결정하는 최고의 방법이 아닌 경우가 있다. 예를 들어, 반품 주문을 완료한 이후에 발생하는 저장이나 문서화 단계와 같은 후위 액티비티들이 있을 수 있다. 이러한 케이스에서 ‘Order completed’는 대상 프로세스의 최종 단계가 될 수 없다. 그러므로 앞에서 설명한 종점 필터를 적용한다면 이러한 케이스는 선별되지 않을 것이다.
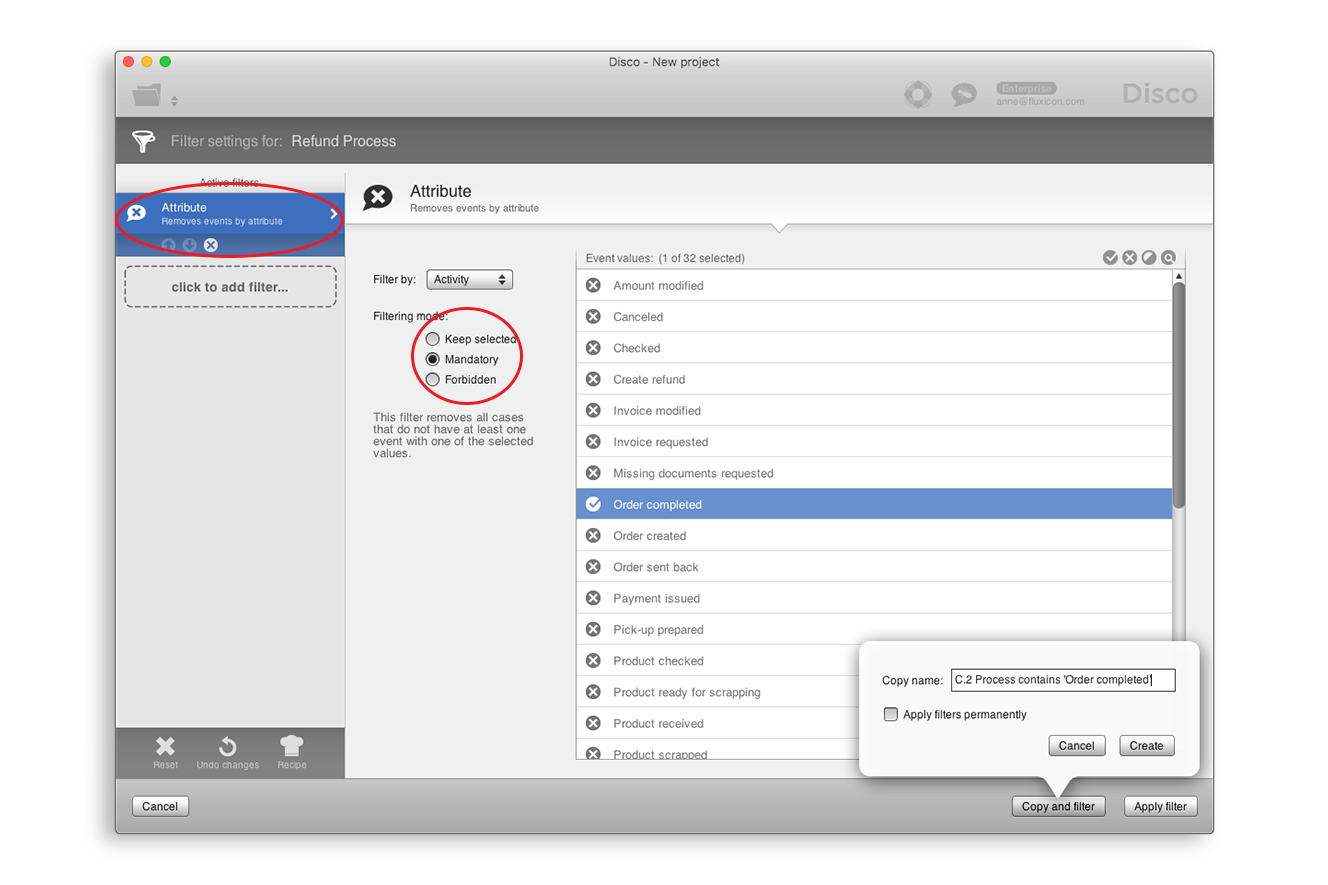
[그림 7] ‘Order completed’를 반드시 포함하는 케이스 선별
만약 분석 대상 프로세스의 완료를 의미하는 하나 이상의 마일스톤 액티비티가 발생했는가에 주로 관심을 가진다면 여러분은 ‘Mandatory’ 모드에서 속성 필터(Attribute filter)를 이용하면 된다([그림 7] 참조). 이 필터를 통해서 여러분은 선택한 액티비티들 중 하나 이상이 발생한 케이스들을 선별할 수 있다.
[그림 7]의 필터를 적용하면 우리는 이전에 적용한 종점 필터와는 조금 다른 결과를 얻는다. 333개의 케이스가 아니라, 334개의 케이스가 선별된다. [그림 8]에 나타난 것처럼, 추가된 하나의 케이스는 ‘Warehouse’ 액티비티로 완료된다.
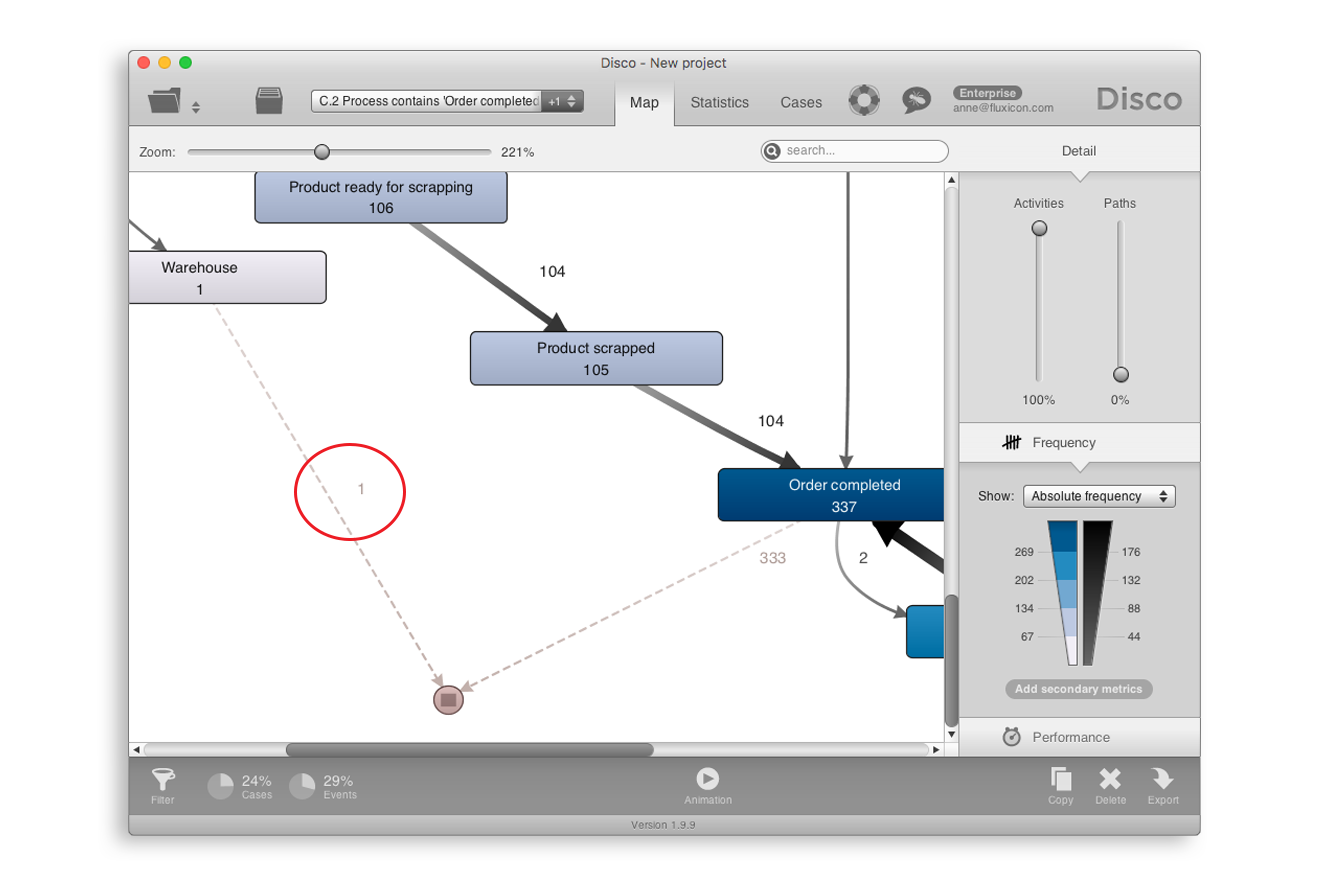
[그림 8] 속성 필터를 적용한 결과
‘Warehouse’ 액티비티로 끝나는 케이스를 자세히 조사하기 위해 이 액티비티에서 시작되는 점선을 클릭한 후에 ‘Filter for this end activity...’를 클릭하면 된다([그림 4] 참조). [그림 9]와 같이, 우리는 해당 케이스의 수행기록을 확인할 수 있고, ‘Order completed’가 실제 발생했음을 알 수 있다.
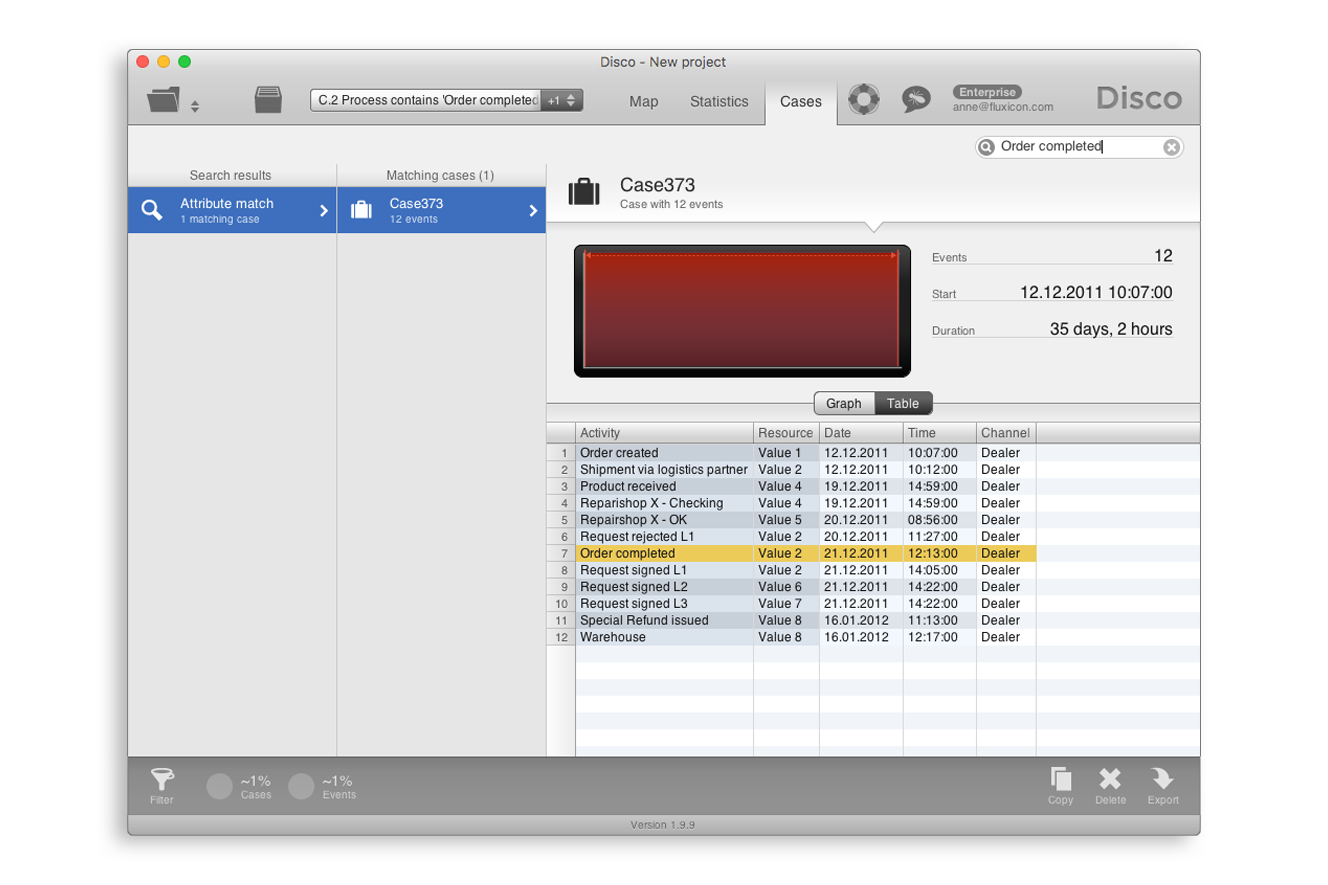
[그림 9] ‘Order completed’가 중간에 수행되고, ‘Warehouse’로 끝난 케이스의 수행내역
컷오프(Cut Off)
반품 프로세스는 전자제품 제조업체의 고객이 제품 구매 후에 고장 난 제품에 대한 반품 요청을 처리하고 지불하는 과정이다. 그러므로 여러분은 고객 관점에서 이 프로세스를 분석할 수도 있다. 이러한 관점에서 고객은 환불금을 돌려받았을 때 비로소 이 프로세스가 “완료”되는 것으로 생각한다.
고객 관점에서 데이터를 분석하기 위해 우리는 3개의 지불 액티비티(즉, ‘Payment issued’, ‘Refund issued’, ‘Special Refund issued’)에 집중할 수 있다([그림 10] 참조). 프로세스 맵에서 이 액티비티들을 찾아 보면 이 액티비티들 이후에 수행된 몇몇 액티비티들이 있음을 알 수 있다. 때때로 후방처리의 지연이 상당히 길 수 있다(예를 들어, ‘Payment issued’ 단계 이후에 평균 7.5일이 걸림). 그러나 고객 관점에서 이러한 지연은 중요하지 않다. 왜냐하면 고객은 환불금을 이미 받았기 때문이다. 그러므로 고객에게 중요한 프로세스의 부분에 분석을 집중하기 위해 우리는 ‘Trim longest mode’의 종점 필터를 사용할 수 있다([그림 11] 참조).
종점 필터의 모드를 ‘Discard cases’에서 ‘Trim longest’로 변경하면 왼쪽의 ‘Start event values’와 오른쪽의 ‘End event values’에서 모든 액티비티들을 선택할 수 있다. ‘Start event values’에서는 모든 액티비티들을 선택하고, ‘End event values’에서는 3개의 지불 액티비티들을 선택함으로써 우리는 고객 관점에서 반품 프로세스를 분석할 수 있다.
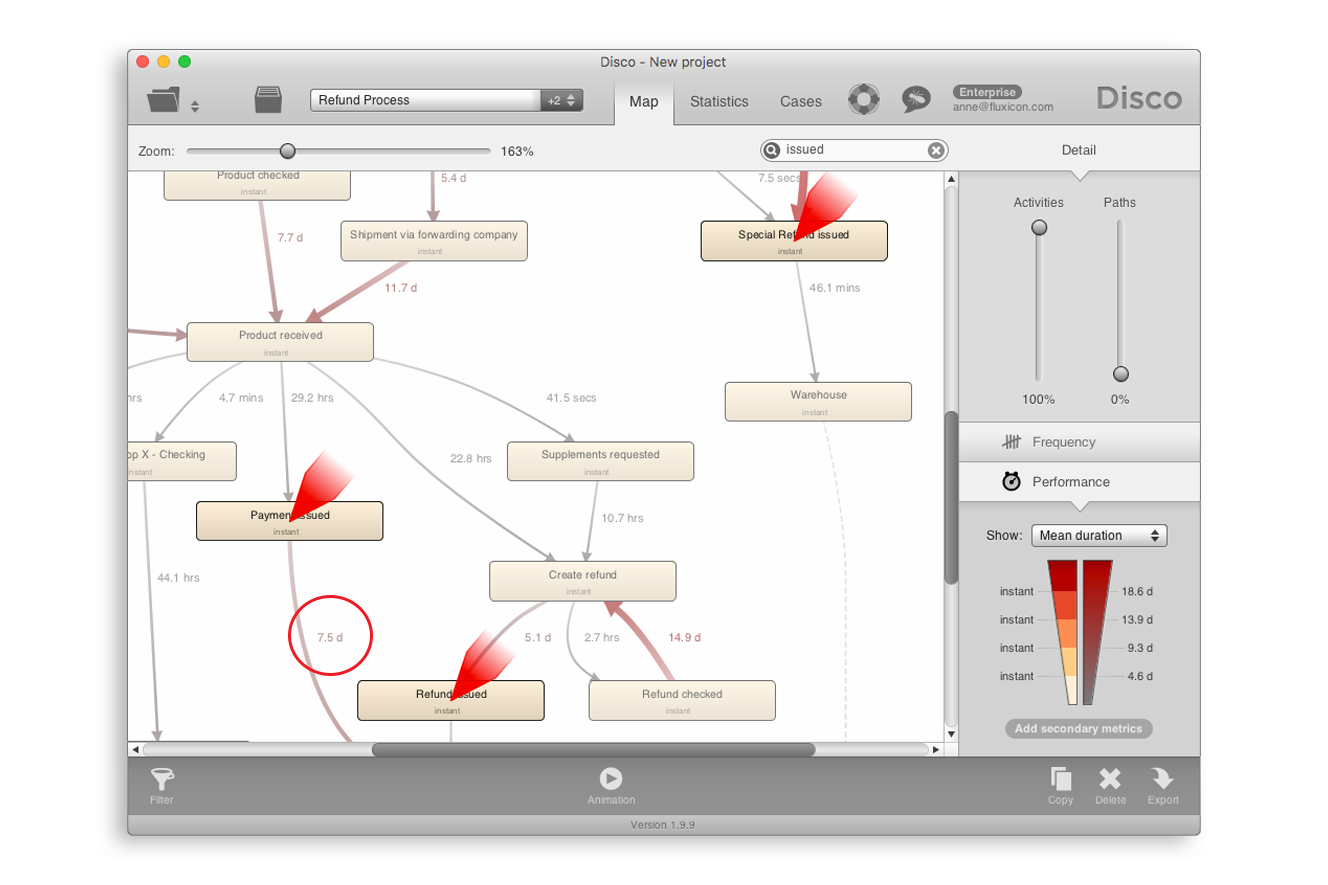
[그림 10] 프로세스 맵에서 검색된 3개의 지불 액티비티
결론적으로, 3개의 지불 액티비티들 중 가장 마지막에 발생한 지불 액티비티 이후에 발생했던 모든 액티비티들은 차단(cut off)된다. 이를 통해서 3개의 지불 액티비티가 종료 단계가 되는 새로운 프로세스 맵이 발견된다([그림 12] 참조).
사실, [그림 11]의 필터에서 선별된 케이스들은 ‘Mandatory’ 모드에서 3개의 지불 액티비티를 선택하는 속성 필터의 결과와 동일하다. 그러나 [그림 11]의 필터는 3개의 지불 액티비티 이후에 수행된 다른 액티비티들을 차단하기 때문에 여러분은 고객 관점에서 적절한 프로세스의 부분에만 집중해서 분석을 진행할 수 있다.
- 프로세스 맵은 3개의 지불 액티비티 이후에 발생한 후위 처리(back-end) 액티비티들을 더 이상 보여주지 않는다. 그러므로 병목 분석(bottleneck analysis)을 통해 우리는 프로세스 맵에서 집중해야 할 정확한 지점을 발견할 수 있다.
- 이제 통계 뷰의 케이스 수행기간은 반품 주문의 생성부터 고객이 환불금을 돌려받은 순간까지의 기간을 나타낸다.
- 베리언트들은 반품 주문의 생성부터 지불 액티비티까지의 가능한 프로세스 시나리오를 보여준다. 그러므로 이러한 베리언트들은 고객 관점에서 더욱 큰 의미를 가진다.
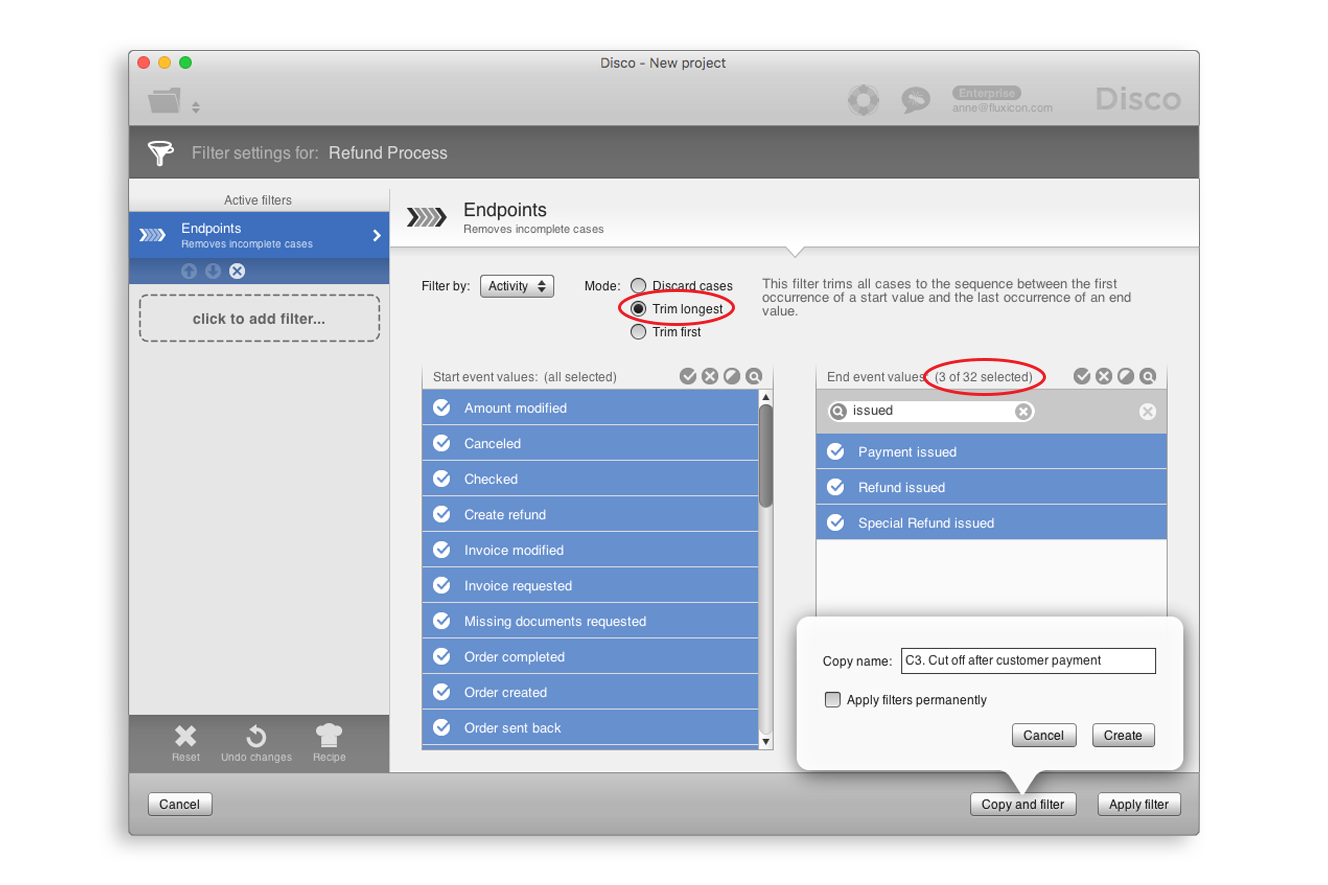
[그림 11] ‘Trim longest’ 모드의 종점 필터
X 기간 이상 미완료됨
(첫 페이지의 세 번째 이유 때문에) 특정 기간 동안 어떤 액티비티도 수행되지 않는다면 마지막 수행된 액티비티가 종료 단계로 간주될 수도 있다. 예를 들어, 반품 주문을 처리하기 위해 고객에게 구매 영수증과 같은 빠진 문서를 요청할 수 있다. 그러나 고객이 이러한 요청에 응답하지 않는다면 ‘빠진 문서 요청’(즉, ‘Missing documents requested’)이 종료 액티비티로 간주될 수도 있다.
만약 ‘Missing documents requested’ 액티비티가 프로세스의 마지막 단계로 수행된 이후에 1달 동안 어떤 것도 발생하지 않은 케이스의 분석에 초점을 맞추고 싶다면 우리는 다음과 같은 방식으로 필터들의 조합을 활용할 수 있다.
먼저, [그림 13]에 나타난 것처럼, 종점 필터를 추가한다.
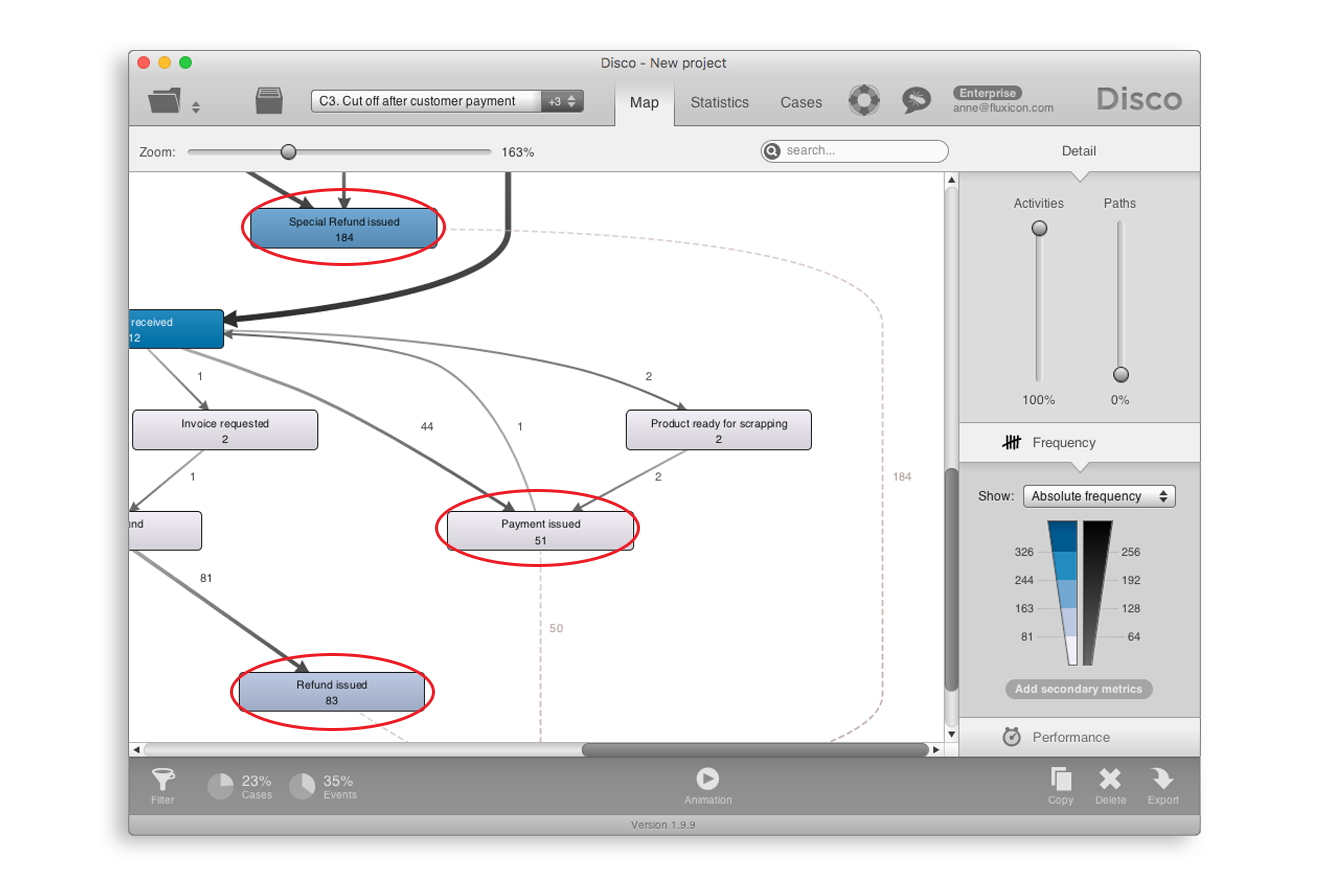
[그림 12] 3개의 지불 액티비티를 종료 지점으로 가지는 프로세스 맵
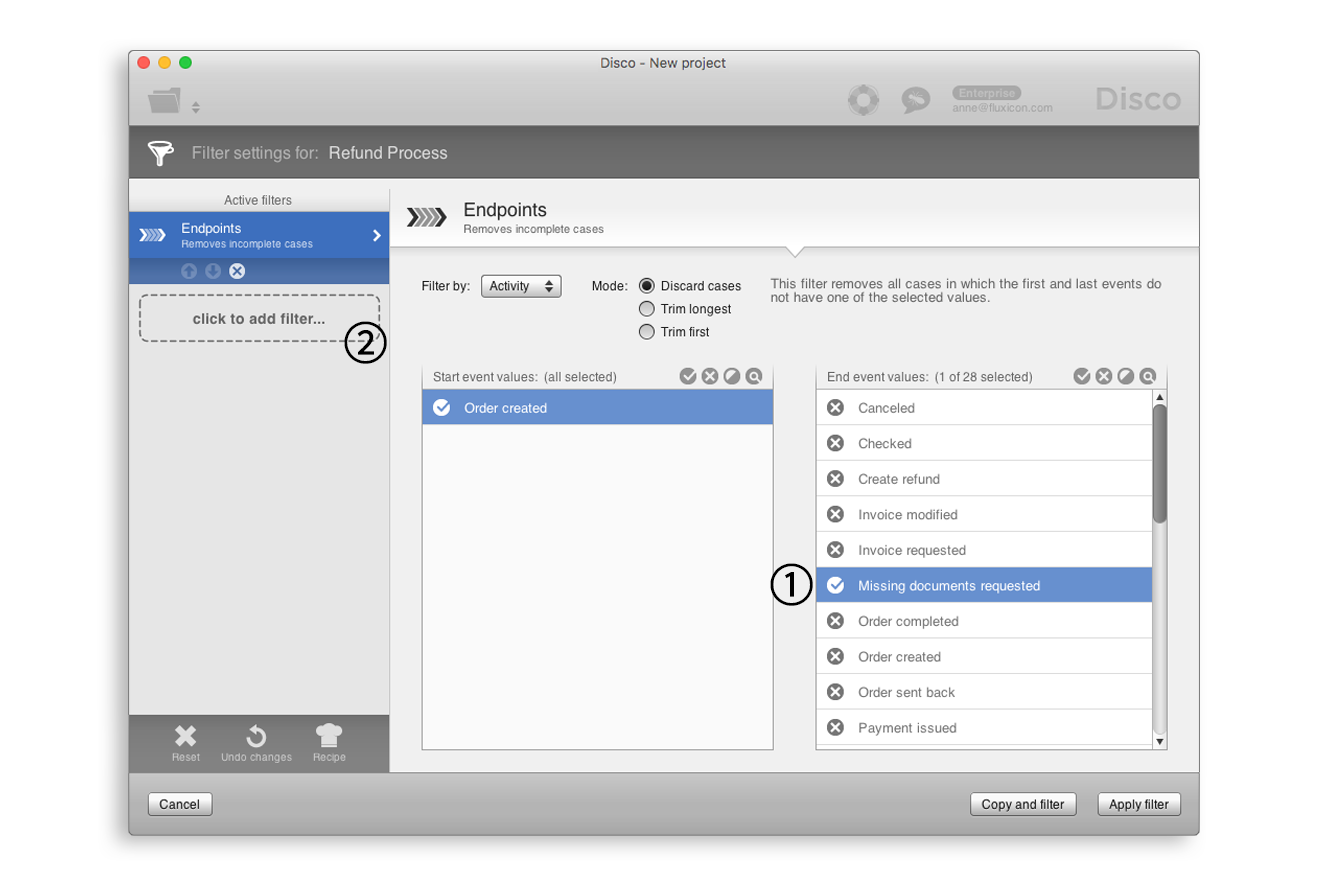
[그림 13] 종점 필터의 추가
그런 다음에 ‘click to add filter...’ 버튼을 클릭하여 두 번째 필터인 타임프레임 필터를 추가한다([그림 14] 참조). [그림 14]와 같이 설정하면 ‘Missing documents requested’로 완료된 케이스들 중에서 마지막 단계(즉, ‘Missing documents requested’)가 한 달 이상 전에 수행된 케이스가 선별된다.
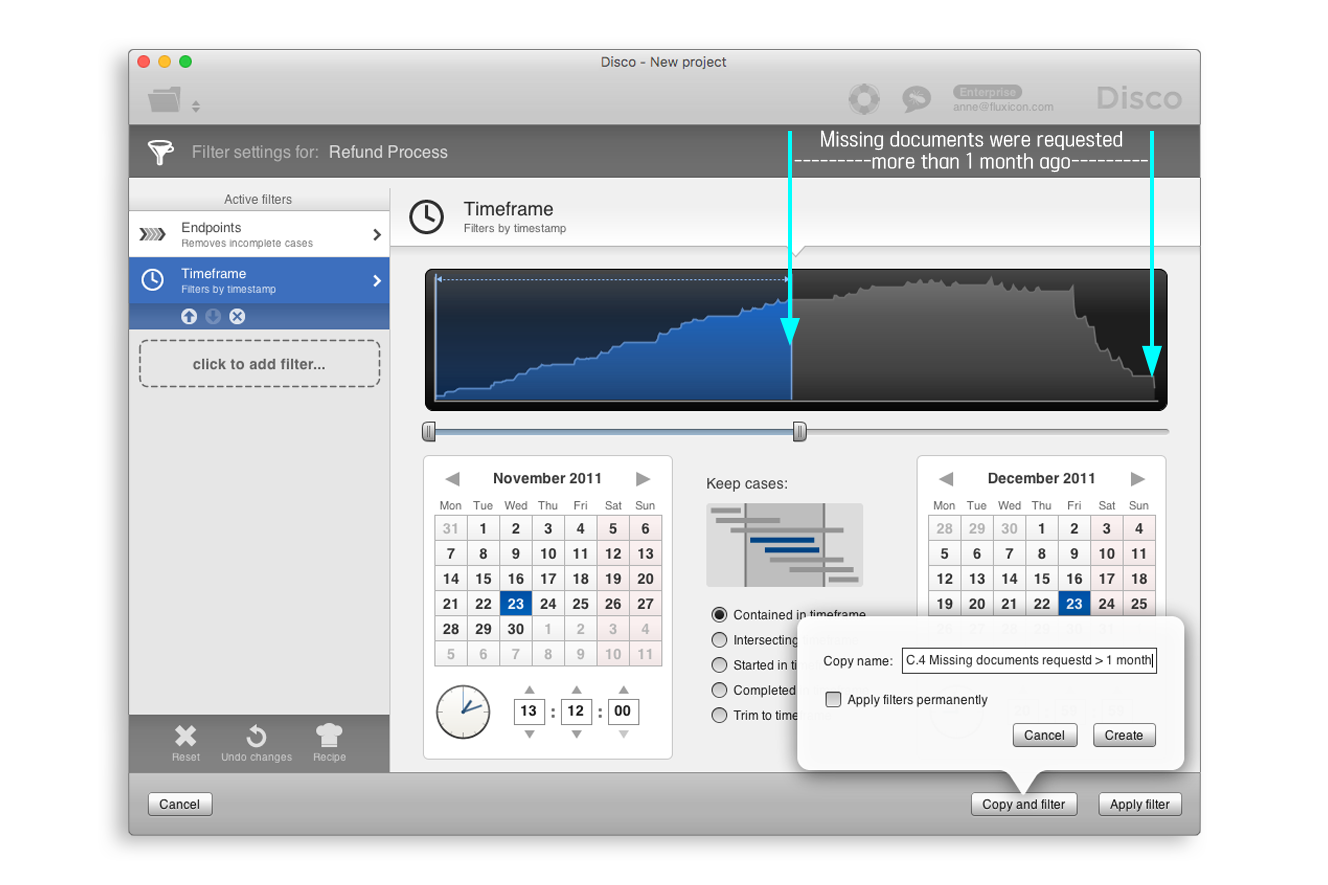
[그림 14] 타임프레임 필터의 추가
4. 불완전 케이스가 제거되지 않아야 할 때
프로세스 마이닝 분석을 수행할 때 데이터셋에서 불완전 케이스를 제거하지 않아야 하는 상황들이 있다. 두 개의 예를 들면 다음과 같다.
- 직무분리의 검증과 같은 많은 컴플라이언스 질문들은 전체 데이터셋에서 검증되는 것이 좋다. 분석 대상 프로세스의 어떤 부분에서 준수되어야 할 컴플라이언스 규칙이 있다면 이 규칙은 완료되지 않은 케이스들에 대해서 여전히 적용되어야만 한다. 그러므로 완료된 케이스에 대해서만 컴플라이언스 분석을 집중한다면 여러분은 불필요하게 여러분의 분석을 제한할 수도 있다. 예를 들어, 반품 프로세스에서 고객은 고장 난 제품을 제조업체에게 반품한 이후에 환불금을 받아야만 한다. 이 컴플라이언스 규칙은 ‘Order completed’ 상태에 도달하지 않은 모든 반품 주문에 대해 유효하다. 그러므로 모든 이탈을 포착했음을 확실히 하기 위해 여러분은 불완전 케이스를 포함하는 전체 데이터셋을 기반으로 컴플라이언스 분석을 수행할 필요가 있다. 그러나 컴플라이언스 규칙의 전제조건이 무엇인가를 이해하고, 전제조건이 만족되는 방식으로 여러분의 데이터셋을 필터링하도록 주의하라. 예를 들어, 여러분의 구매 프로세스는 어떤 변경(예, 날짜나 금액 변경)이 발생한 이후에 이에 대한 승인을 요구하는 컴플라이언스 규칙을 가지고 있다고 하자. 만약 발생한 어떤 변경에 대한 승인이 아직 일어나지 않았다고 해도 해당 구매오더가 여전히 진행 중이라면 승인은 추후에라도 발생할 수 있는 것이다. 그러므로 여러분은 컴플라이언스 규칙이 어떤 마일스톤 액티비티(예, 송장에 대한 지불이 이루어지기 전)에서 명확히 준수되어야 하는가를 생각해야 한다. 그리고 컴플라이언스 분석을 시작하기 전에 이러한 전제조건에 맞게 여러분의 데이터를 필터링해야 한다.
- 여러분은 사실 일부 분석 질문들에 대해서는 불완전 케이스에 집중하기를 원할 수도 있다. 예를 들어, 여러분은 미완료 케이스(open cases)가 어떤 곳에서 멈추어져 있는지, 얼마나 오랫동안 멈추어져 있는지, 전체적으로 얼마나 오랫동안 미완료 상태였는지를 분석하길 원할 수도 있다.
마지막으로, 불완전 케이스를 제거한 이후에도 여러분의 데이터셋이 대표성을 갖는가를 검증하는 것을 잊지 말라. 예를 들어, 80%의 케이스가 불완전할 때 여러분의 프로세스 분석을 나머지 20%에 기반을 두고 진행하는 것은 매우 위험할 수 있다.
만약 현재 확보된 데이터셋이 충분한 완료 케이스를 포함하지 않는다면 여러분은 데이터 추출 단계로 되돌아가서 추출 대상 기간을 늘려서 대표성을 확보해야 할 수도 있다.