

프로세스 마이닝을 통한 프로세스 복잡성 관리 방안
- 작성일2021/12/29 15:36
- 조회 574
여러분의 프로세스 마이닝 도구에 데이터셋을 가져와서 “스파게티” 프로세스를 발견한 경험이 있는가? 종종 현실의 프로세스들은 매우 복잡해서 프로세스 마이닝을 통해서 발견된 프로세스 맵도 너무나 복잡하여 이것을 이해하고 이용할 수 없을 수도 있다. 예를 들어, 여러분이 발견한 프로세스는 아래와 같을 수 있다.
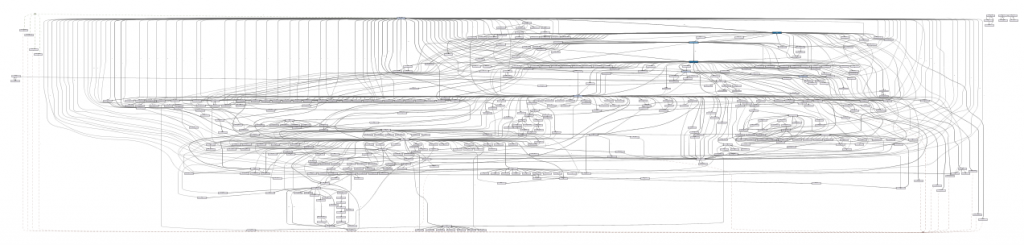
[국내 공공기관의 실제 프로세스의 일부]
위의 그림의 문제는 그림 자체가 잘못되었다는 것이 아니다. 사실 이것이 실제 업무 수행의 모습니다. 진정한 문제는 이러한 프로세스 맵은 유용하지 않다는 것이다. 왜냐하면 이 맵은 너무 복잡해서 유용한 통찰력이나 실행 가능한 정보를 도출할 수 없기 때문이다. 관리할 수 있는 조각들을 얻기 위해서 우리가 해야 할 일은 이러한 복잡한 프로세스 맵을 분할하고 단순화시켜야 한다는 것이다.
여러분은 이 아티클에서 복잡한 프로세스 맵의 단순화를 위한 9가지 전략들을 배우게 될 것이다. 이러한 전략들은 여러분이 필요로 하는 분석 결과들을 얻을 데 도움을 줄 수 있다. 우리는 프로세스 마이닝 소프트웨어인 Disco에서 이러한 전략들을 어떻게 적용할 수 있는가를 보여줄 것이다.
Part Ⅰ: Quick Simplification Methods
1) 상호작용 단순화 슬라이더(Interactive Simplification Sliders)
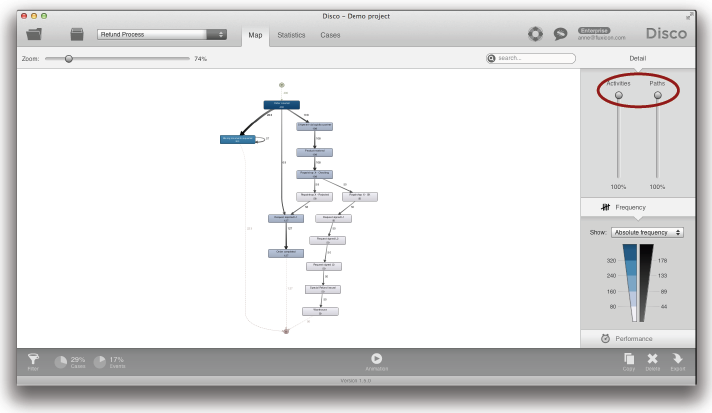
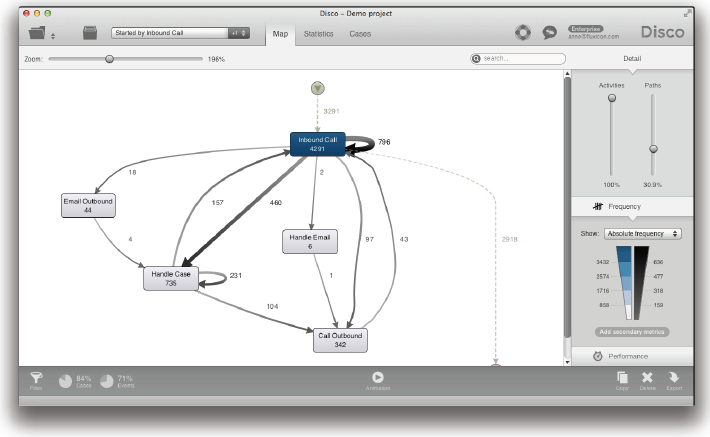
먼저, 빠르게 단순화된 프로세스 맵을 얻을 수 있는 2개의 단순화 방법들이 있다. 첫 번째 방법은 Disco의 맵 뷰에 내장된 상호작용 단순화 슬라이더를 이용하는 것이다 (아래의 그림 참조).
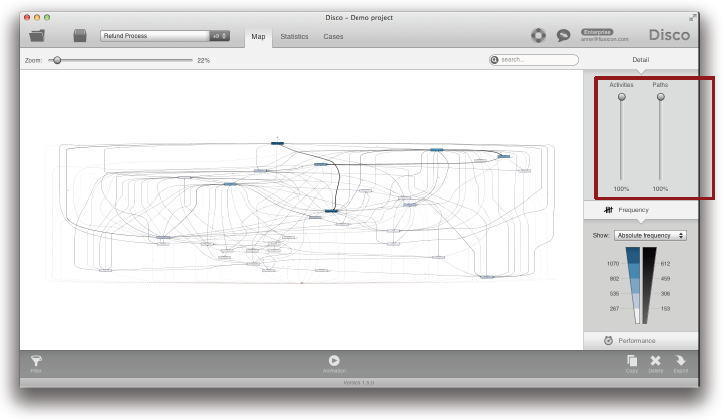
Disco Miner는 Christian’s Fuzzy Miner [1]에 기반을 두고 있다. Fuzzy Miner는 “map metaphor” 개념을 도입했고, 프로세스 단순화와 빈번한 활동들과 경로들의 강조와 같은 발전된 기능들을 포함하고 있다. 그러나 Disco Miner는 많은 방식에서 Fuzzy Miner보다 크게 개선되었다.
하나의 중요한 차이점은 액티비티와 경로 슬라이더를 100%까지 끌어올린다면 여러분은 대상 프로세스의 정확한 모습을 볼 수 있다. 정확히 수행되었던 대로, 대상 프로세스의 온전한 그림이 보여진다. 이 프로세스 맵은 참조 모델로서 매우 중요하고 여러분의 데이터와 1대1로 대응된다.
그러나 나중에 언급될 단순화 전략들 중의 어떤 것도 적용되지 않는다면 온전한 프로세스는 종종 너무 복잡해서 100% 구체적인 수준에서 이해될 수 없다. 그러나 상호작용 단순화 슬라이더를 이용한다면 여러분은 복잡한 대상 프로세스에 대한 개략적인 모습을 빠르게 파악할 수 있다. 우리는 여러분이 먼저 경로 (Paths) 슬라이더를 내릴 것을 권장한다.
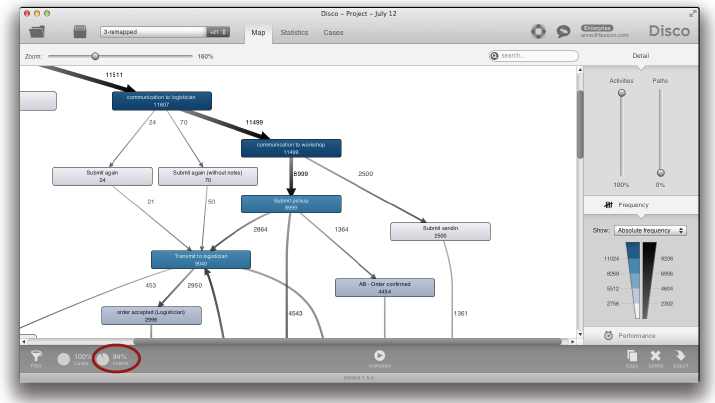
경로 슬라이더를 내리면 액티비티들 사이의 덜 빈번한 전이들 (transitions)을 감춤으로써 프로세스 맵에서 경로들을 점진적으로 줄일 수 있다. 경로 슬라이더가 가장 낮은 지점에 도달하면 여러분은 가장 빈번한 프로세스 흐름들만을 볼 수 있다. 따라서 이전의 “스파게티” 프로세스 맵은 크게 단순화되어 알아보기 쉽고 이해할 수 있는 프로세스 맵이 도출되었음을 알 수 있다 (아래의 그림 참조).
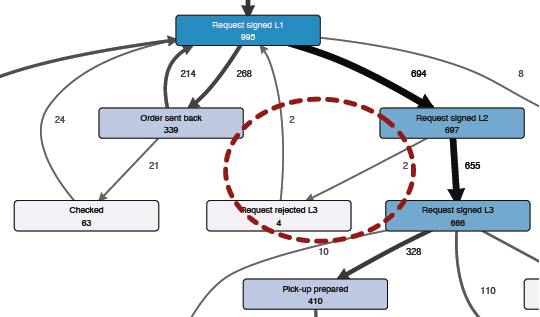
여러분이 관심을 기울일 것은 보여지는 경로들 중에서 일부는 여전히 매우 빈번하지 않을 수 있다는 것이다. 예를 들어, 빈도수가 2인 두 개의 경로들이 위의 그림에 나타나 있다. 이러한 경로들이 나타나는 이유는 다음과 같다. 스마트한 경로 단순화 슬라이더는 프로세스 맥락을 고려한다. 액티비티 단순화 슬라이더가 100%이므로 수행 빈도가 매우 낮은 액티비티인 ‘Request rejected L3’ (4번 수행됨)도 프로세스 맵에 나타나야 한다. 수행 빈도가 낮은 액티비티들이 프로세스의 나머지 부분과 단절되어 별도로 표시되는 것은 유용하지 않다. 이런 이유로 빈도수가 낮은 액티비티를 보여줄 때 이와 연결되는 빈도수가 낮은 경로들을 보여주는 것이다.
경로 슬라이더의 이용은 매우 중요하다. 왜냐하면 경로 슬라이더의 적절한 조절은 프로세스에서 발생했던 모든 것 (즉, 수행된 모든 액티비티들)을 보여주면서 이들 사이의 중요 흐름들을 표시하는 이해하기 쉬운 프로세스 맵을 제공할 수 있기 때문이다.
여러분은 종종 모든 액티비티들을 보이면서 (액티비티 슬라이더: 100%), 중요 프로세스 흐름들 (프로세스 복잡성에 따라서 경로 슬라이더를 가장 낮은 점에 위치하거나 약간 올림)만을 보여주는 프로세스 맵을 빠르게 얻는 것이 최고의 결과를 제공한다는 것을 발견하게 될 것이다.
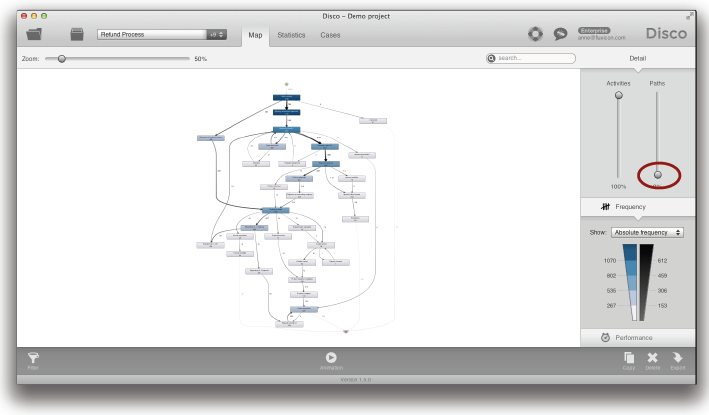
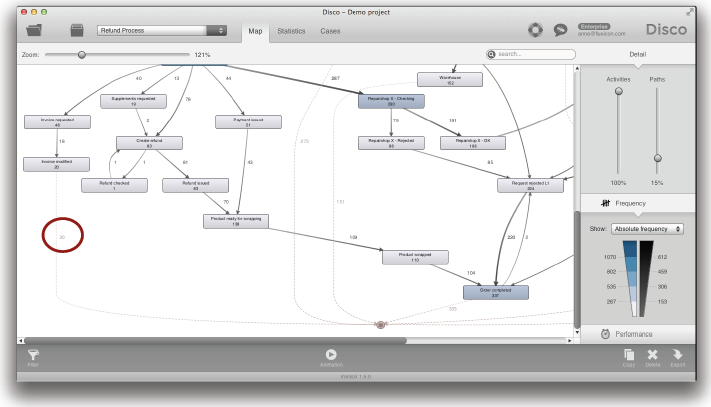
그러나 여러분의 프로세스가 많은 액티비티들을 가지고 있거나 여러분이 프로세스 맵을 더욱 단순화시키기를 원한다면 여러분은 액티비티 슬라이더를 낮춤으로써 액티비티들의 수를 줄일 수 있다 (아래의 그림 참조).
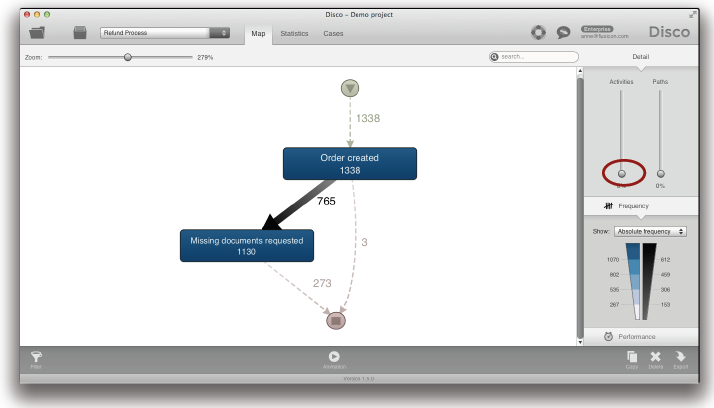
액티비티 슬라이더가 가장 낮은 지점에 위치하면 가장 빈번하게 수행된 프로세스 variant의 활동들만이 보여진다 (두 번째 전략 참조). 이것은 가장 빈번한 경로 상에서 처음부터 끝까지 수행되었던 액티비티들만을 보여준다는 것을 의미한다. 그러므로 액티비티 슬라이더의 이러한 설정은 여러분에게 프로세스의 진정한 핵심 흐름을 보여줄 수 있다 (덜 빈번한 경로들뿐만 아니라, 덜 빈번한 액티비티들로부터 추상화될 수 있음).
예를 들어, 처음의 “스파게티” 프로세스 맵은 액티비티 슬라이더를 최대한 낮춤으로써 2개의 액티비티들 (‘Order created’와 ‘Missing documents requested’)로 크게 단순화될 수 있다 (위의 그림 참조).
2) 핵심 Variants에 집중하기
단순화된 프로세스 맵을 빠르게 얻기 위한 다른 방법은 대상 프로세스의 핵심 variants에 집중하는 것이다. 여러분은 Disco의 케이스 뷰에서 variants를 발견할 수 있다.
예를 들어, 가장 빈번한 variant (Variant 1)의 한 케이스가 아래의 그림에 제시되어 있다: 단지 두 개의 액티비티들(‘Order created’와 ‘Missing documents requested’)로 구성되어 있다 (즉, 대부분의 케이스들은 이상하게도 고객의 피드백을 기다리고 있다. 그러나 우리는 지금 당장 이러한 발견에 집중하지 않을 것이다).
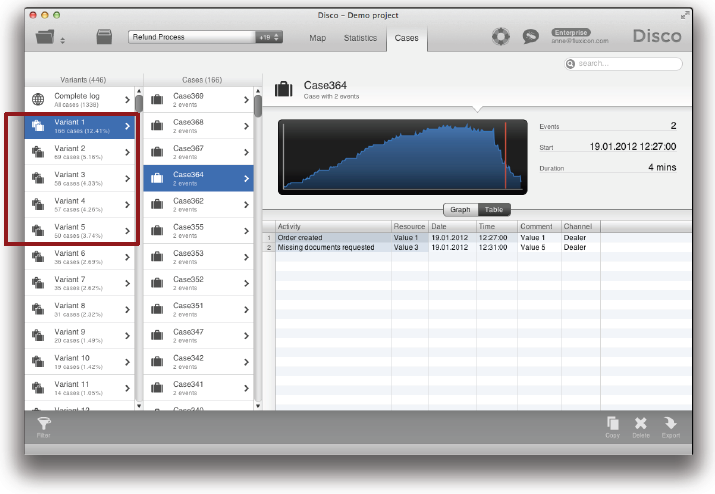
variant들의 케이스 빈도와 비율을 보면 여러분은 가장 빈번한 variant가 대상 프로세스의 12.41%, 두 번째 빈번한 variant가 5.16%를 차지함을 알 수 있다. 대부분의 구조화된 프로세스에서 상위 5개에서 10개의 variants가 전체 프로세스의 70 ~ 80%를 차지하는 것이 일반적이다. 그러므로 프로세스의 단순화를 위해서 variants를 활용하는 것은 좋은 아이디어가 된다.
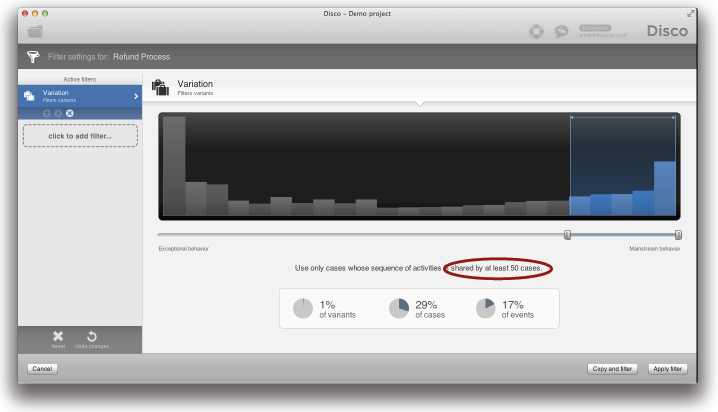
여러분은 ‘Variation 필터’를 이용함으로써 Disco에서 핵심 variants에 쉽게 집중할 수 있다 (아래의 그림 참조). 예를 들어, 최소한 50개의 케이스들이 공유하는 variant들만을 유지함으로써 우리는 상위 5개의 variant들에만 집중할 수 있다.
[code]주의: 이 전략은 구조화된 프로세스에 적용된다. 비구조화된 프로세스(예, 병원의 환자 진단과 치료 프로세스나 웹사이트의 클릭 스트림)에서 여러분은 종종 지배적인 variants를 전혀 가질 수 없다. 모든 케이스가 유일하게 된다. 비구조화된 프로세스에서 variant 기반의 단순화는 완전히 유용하지 않다. 그러나 첫 번째 전략인 상호작용 단순화 슬라이더는 여전히 효과가 있다 (이 전략은 항상 효과가 있다).[/code]
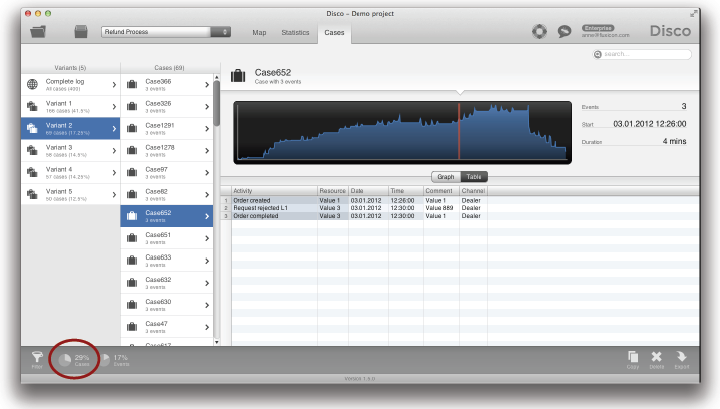
단지 상위 5개의 variant들만이 보유되었고, 전체 446개의 variant들 중에서 이 5개가 전체 케이스들의 29%를 차지하고 있다 (위의 그림 참조). 케이스 뷰에서 맵 뷰로 다시 돌아오면 여러분은 상위 5개의 variant들에 대한 프로세스 맵을 볼 수 있다 (아래의 그림 참조).
여기서의 요령은 위와 같은 방식으로 여러분은 100% 구체성을 가지는 프로세스 맵을 쉽게 만들 수 있다는 것이다 (액티비티와 경로 슬라이더들이 완전히 끌어올려졌음) – 물론 ‘Variation 필터’에 의해서 유지된 variant들에 대해서만 적용된다.
이러한 방식은 프로세스 마이닝에 익숙하지 않는 사람들을 위해서 프로세스 맵을 빠르게 내보낼 필요가 있을 때 특히 유용하다. 만약 100% 구체성을 가지는 프로세스 맵을 전달하면 모든 숫자들이 더해질 수 있고 (어떤 경로들도 숨겨지지 않음), 여러분은 “스파게티” 프로세스가 무엇이고 이러한 프로세스가 단순화될 필요가 있다는 이유를 설명할 필요가 없게 된다. 여러분은 그들에게 PDF 파일로 내보내어진 프로세스 맵을 쉽게 보낼 수 있고, 예를 들어, “대상 프로세스의 80%가 어떻게 흘러가는가를 보여주는 맵” (물론 여러분의 variant(s) 선택이 다루는 케이스들의 수에 따라서 %가 달라짐)이라고 말할 수도 있다.
덜 빈번한 액티비티들은 매우 예외적인 variant들에 포함되어 있다. 그러므로 핵심 variant들에 집중할 때 여러분은 이러한 액티비티들을 볼 수 없다는 한계를 가진다.
Part Ⅱ: Remove Incomplete Cases
3) 불완전한 케이스들의 제거
특히 새로운 데이터셋을 받아서 첫 번째 프로세스 맵을 만들고 싶다면 여러분은 일반적으로 구체적인 분석을 즉시 시작하기를 원하지 않을 것이다. 예를 들어, 여러분은 종종 추출된 데이터가 올바른가를 검증하기를 원하거나 프로세스 소유자에게 발견된 프로세가 어떻게 보이는가에 대한 첫 번째 모습을 빠르게 보여줄 필요가 있을 것이다.
분명히 복잡한 프로세스 맵은 이러한 것을 수행할 때 방해가 된다. 불완전한 케이스들의 필터링은 실제적인 분석을 위한 일반적인 준비 단계이다. 그러나 이러한 필터링은 단순한 프로세스 맵을 도출하는 것에도 도움을 줄 수 있다. 그 이유는 다음과 같다.
많은 경우에 IT 시스템에서 새롭게 도출된 데이터는 완료되지 않은 케이스들을 포함하고 있다. 이들은 업무 수행의 어떤 상태에 있기 때문에 우리가 기다린다면 새로운 프로세스 단계들이 나타날 것이다. 이러한 데이터는 또한 완료되었으나, 불완전한 시작점들을 가질 수 있다. 왜냐하면 데이터 추출 대상 기간 이전에 업무가 시작된 케이스들이 있기 때문이다.
예를 들어, 프로세스 수행시간(duration)의 분석을 위해서 불완전한 케이스들을 제거하는 것이 매우 중요하다. 이렇게 하지 않는다면 불완전한 케이스들의 특히 빠른 수행시간들이 잘못된 방식으로 평균 프로세스 수행시간을 감소시키게 될 것이다. 이와 함께, 불완전한 케이스들은 프로세스 종료 지점으로의 많은 추가적인 경로들을 야기함으로써 프로세스 맵 배치를 확대할 수 있다.
그 이유를 이해하기 위해서 아래의 프로세스 맵을 보자. 이 맵은 일반적인 종료 활동인 ‘Order completed’ 옆에 프로세스의 마지막 단계로 수행되었던 몇 개의 다른 활동들이 있음을 보여주고 있다 – 이 활동들은 프로세스 맵의 하단에 위치한 종료 지점으로 향하는 점선과 연결된 활동들임. 예를 들어, ‘Invoice modified’는 20개의 케이스들에 대해서 프로세스의 마지막 단계이었다 (아래의 그림 참조). 이 활동이 대상 프로세스의 마지막 단계인 것은 이상하지 않는가?
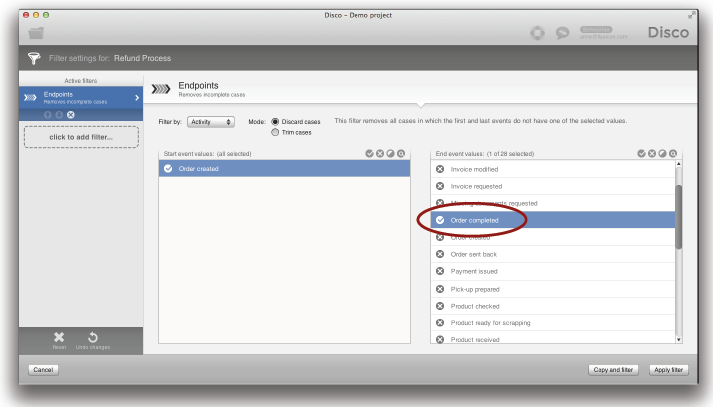
불완전한 케이스들을 제거하기 위해서 여러분은 Disco의 ‘Endpoints 필터’를 추가해서 대상 프로세스의 유효한 시작과 종료 지점들인 시작과 종료 활동들을 선택할 수 있다 (아래의 그림 참조).
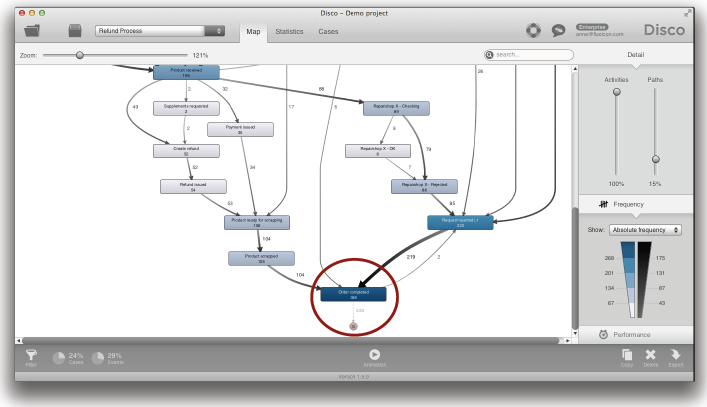
그래프 배치가 단순해지기 때문에 도출된 프로세스 맵도 더욱 단순해질 것이다 (아래의 그림 참조).
Part Ⅲ: Divide and Conquer
4) 다중 프로세스 유형
단순화 전략들의 세 번째 범주는 ‘Divide and Conquer’라고 불린다. 왜냐하면 이 범주는 여러분의 데이터가 더욱 잘 관리될 수 있도록 분석 데이터를 다양한 방식으로 쪼개는 것에 관한 것이기 때문이다.
여러분의 데이터를 쪼개는 첫 번째 방식은 여러분의 프로세스가 매우 종종 다중 프로세스 유형들로 구성됨을 깨닫는 것이다. 여러분은 전체 데이터셋을 하나의 파일에 둘 수 있다. 그러나 이것이 모든 데이터를 반드시 한번에 분석해야 함을 의미하지는 않는다.
예를 들어, 이전의 절들에서 예로 사용된 고객 서비스 반품 프로세스는 대상 프로세스가 시작된 채널을 나타내는 속성을 가지고 있다. 즉, 고객들은 (a) 웹사이트의 폼을 기입함으로써 인터넷을 통하거나, (b) 헬프 데스크(help desk)에 전화를 하거나, (c) 제품을 구매했던 대리점 체인으로 찾아가서 반품 프로세스를 시작할 수 있다.
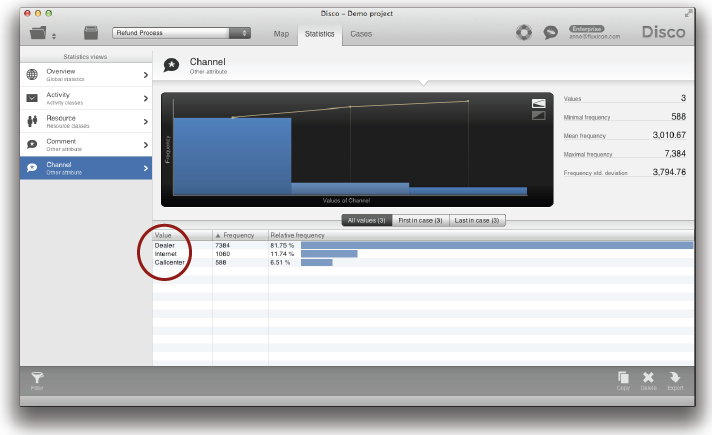
이러한 다양한 채널들에 대한 프로세스들은 동일하지 않다. 예를 들어, 대리점 채널에 대한 반품 프로세스는 다른 두 개의 채널들에 대한 반품 프로세스와 비교할 때 완전히 다른 프로세스 단계들을 가진다. 만약 우리가 이들을 서로 분리하지 않는다면 우리는 다른 프로세스들을 하나의 그림에 가지게 되기 때문에 도출된 프로세스 맵이 불필요하게 복잡하게 된다.
유사한 상황이 IT 서비스 데스크 프로세스에서도 발견될 수 있다. 예를 들어, 변화 관리 프로세스(change management process)에서 실제 프로세스 단계들은 변화 범주에서 따라서 매우 달라질 수 있다: SAP 시스템에 대한 변화를 구현하는 것은 새로운 사용자 계정을 생성하는 것과 동일하지 않다. 변화 범주 속성이 다양한 프로세스 유형들에 대한 데이터를 분리하는데 활용될 수 있다.
여러분은 Disco로 가져온 데이터셋의 프로세스 속성들을 기반으로 쉽게 필터링을 수행할 수 있다. Attribute 필터를 단순히 추가한 후에 ‘Filter by’ 드랍다운 리스트에서 여러분의 프로세스 유형을 나타내는 속성을 선택하라 (아래의 그림 참조).
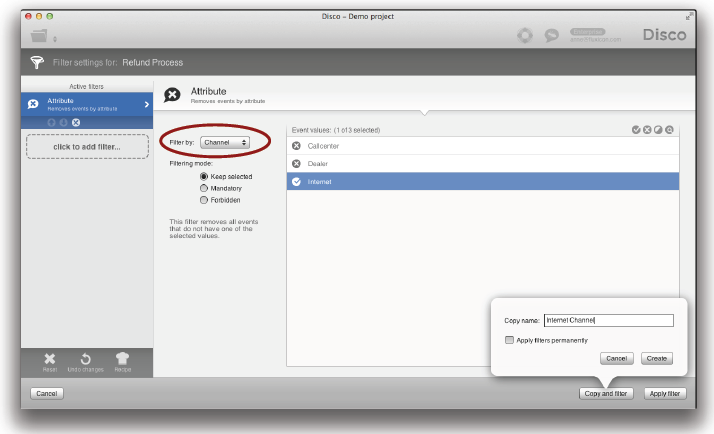
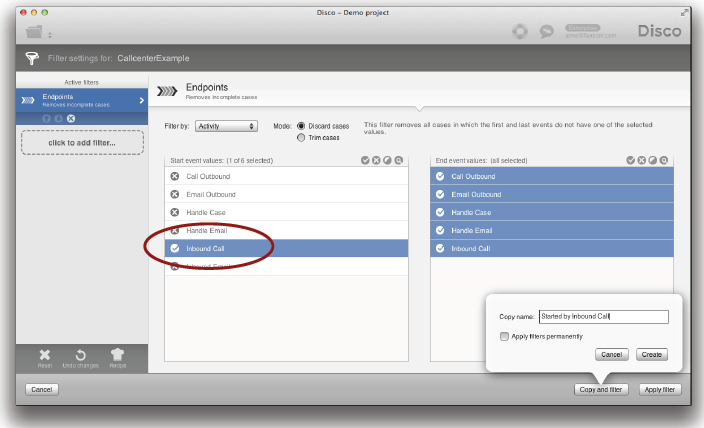
데이터셋을 분리할 때의 권고사항은 복사된 데이터에 필터를 적용하기 위해서 ‘Apply filter’ 버튼 대신에 ‘Copy and filter’ 버튼을 이용하라는 것이다 (위의 그림 참조). 예를 들어, 여러분은 3개의 다른 프로세스 유형들에 각각 1개의 복사본(총 3개의 복사본)을 만들 수 있다. 이후에 여러분은 각 복사본을 기반으로 추가 분석을 수행할 수 있다.
사실, 복사본을 만드는 것은 많은 상황들에서 매우 좋은 아이디어이다. 왜냐하면 모든 복사본은 여러분의 Disco 프로젝트 뷰에 보관되고, 여러분은 쉽게 이들을 선택해서 사용할 수 있고, 여러분의 관찰내용을 노트(notes)에 기록할 수도 있다.
[code]주의: 복사본들은 Disco에서 효율적으로 관리된다 (가능한 경우에 동일한 기반 데이터셋에 대한 포인터들만 유지됨). 그러므로 대규모 데이터셋들에 대해서도 복사본들을 이용하는 것을 두려워할 필요가 없다.[/code]
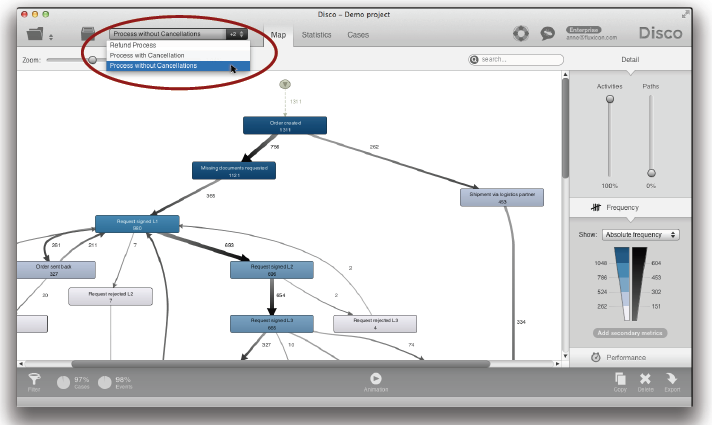
복사본을 만들 때, 분석되는 프로세스 유형 등을 나타낼 수 있는 의미 있는 이름을 짓도록 하라. 이러한 방식으로 여러분은 나중에 복사본들을 빨리 찾을 수 있다. 예를 들어, 인터넷 채널로만 필터링 된 반품 프로세스가 다음과 같다 (케이스들의 6% 차지).
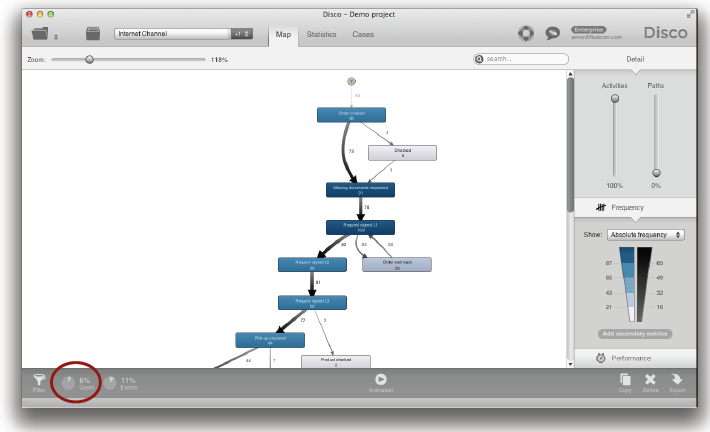
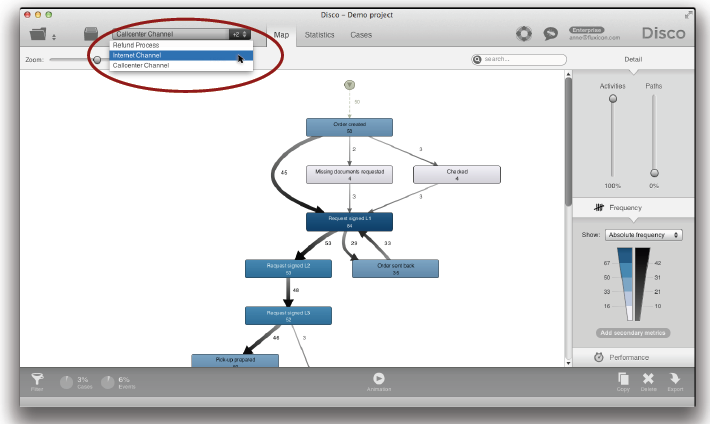
콜센터 채널에 대한 반품 프로세스는 위와 같다. 여러분은 드랍다운 리스트를 통해서 빠르게 프로세스 유형들을 전환할 수 있다.
5) 의미상의 프로세스 Variants (Semantic Process Variants)
데이터셋을 구분하는 두 번째 방법은 “의미상의 프로세스 variants”를 활용하는 것이다. 분리되어야 하는 다중 프로세스 유형들이 있으나, 필터링할 수 있는 프로세스 속성이 없는 경우에 이 방법이 적용될 수 있다. 프로세스에 내재된 행동에 기반을 두고, 비즈니스 관점에서 정의될 수 있는 프로세스 variant들이 암묵적으로 존재하는 경우에 이 방법이 적합하다. 예를 들어, 위에서 논의된 반품 서비스 프로세스에 대해서 프로세스 관리자는 취소된 주문과 취소되지 않은 주문들을 명확히 구분했다. 그들은 취소가 가능한 때에 대해서는 별도의 프로세스 문서화를 수행했다. 그러므로 취소되거나 취소되지 않은 프로세스들은 다른 프로세스 유형들로 간주되었고, 분리될 필요가 있었다.
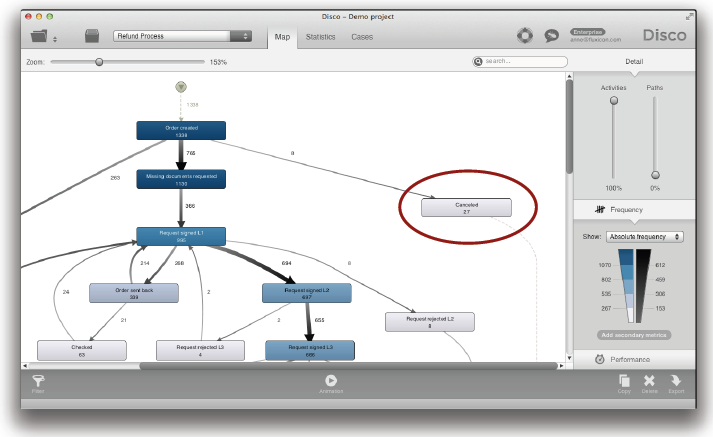
여러분은 Disco에서 어떤 액티비티를 수행하거나 수행하지 않은 케이스들을 필터링하기 위해서 해당 액티비티를 클릭하면 된다. ‘Filter this activity…’ 버튼을 가진 팝오버 다이얼로그 나타난다 (다음 페이지 참조).
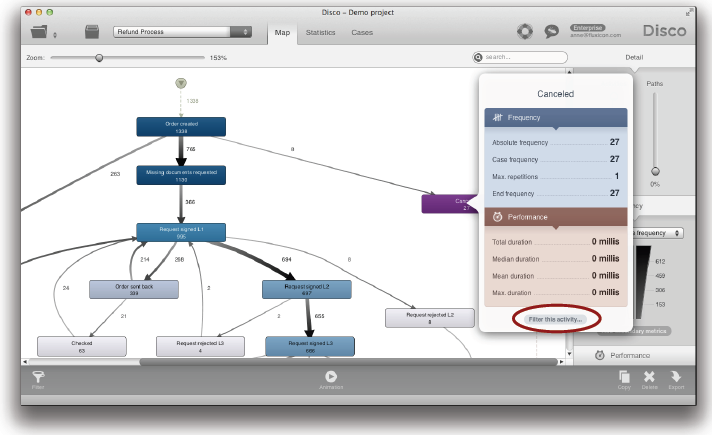
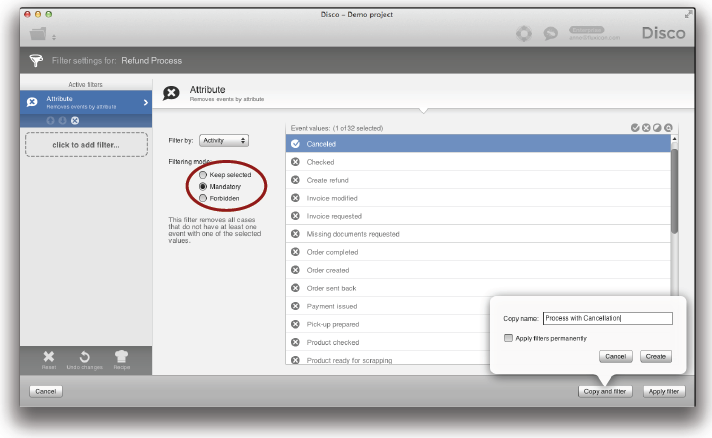
이 버튼을 클릭하면 Mandatory 모드로 미리 설정된 Attribute 필터가 만들어질 것이다 (아래의 그림 참조).
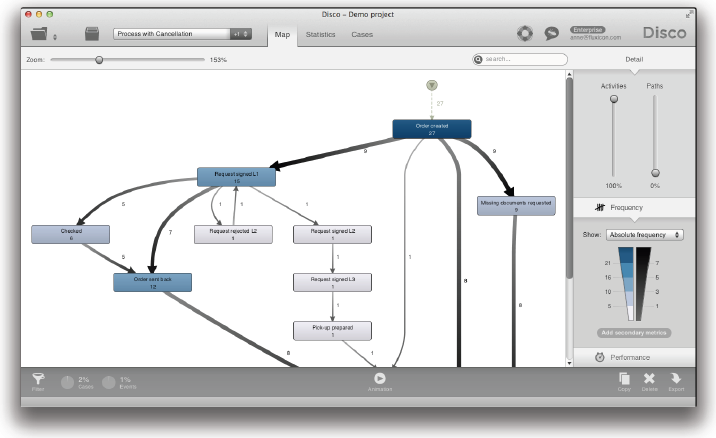
이 필터를 적용하면 프로세스의 어떤 때라도 ‘Canceled’ 액티비티를 수행한 케이스들만이 유지된다 (아래의 그림 참조).
반대로 여러분은 데이터셋에서 ‘Canceled’ 액티비티를 가지는 모든 주문들(케이스들)을 제거하기 위해서 Forbidden 모드를 이용할 수 있다.
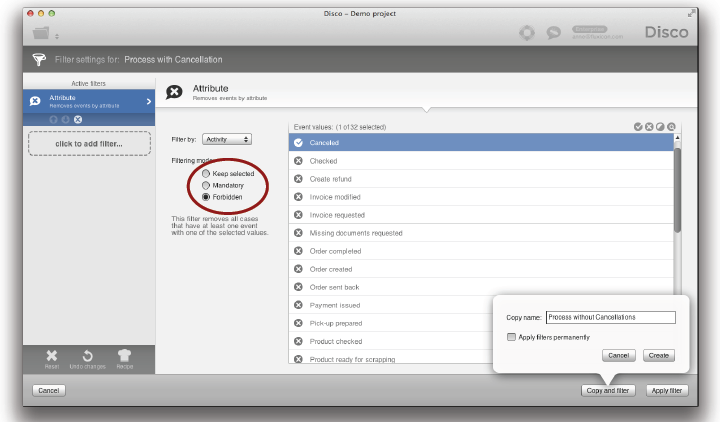
이러한 경우에는 ‘Canceled’ 액티비티를 프로세스의 어떤 때라도 수행하지 않았던 케이스들만이 유지된다. 다시 한번, 여러분은 분리된 데이터셋들을 별도로 저장하기 위해서 복사본들을 만들 수 있고, 취소된 주문들의 프로세스들과 정규 프로세스들에서 발생했던 것들을 별도로 분석할 수 있다.
속성에 의해서 필터링된 프로세스 유형들과 비교할 때, 의미상의 프로세스 variant들은 다루기에 조금 더 까다롭다. 여러분은 프로세스 소유자들이 대상 프로세스를 어떻게 보는가를 이해하기 위해서 이들과 대화할 필요가 있다. 만약 그들이 대상 프로세스를 문서화했다면 그들은 프로세스에 내포된 행동의 어떠한 변형(variation)에 기반을 두고 다양한 버전들을 만들었는가? 그들은 관리자에 의해서 승인될 필요가 있는 신청들을 일반 직원이 직접 처리할 수 있는 표준 신청들과 다르게 보고 있는가?
일단 여러분이 대상 프로세스와 매일 관련되는 이해관계자들에게 해당 프로세스가 어떻게 보여지는가를 이해한다면 프로세스 마이닝은 여러분에게 대상 프로세스를 빠르게 분리할 수 있는 강력한 도구를 제공할 수 있다.
액티비티들의 단순한 존재와 부재에 더하여 여러분은 필터링을 위한 많은 행동 기반의 패턴들을 이용할 수 있다. 예를 들어, ‘Follower 필터’는 시간의 흐름에 따른 액티비티들의 결합에 관한 규칙들을 정의할 수 있고 [어떤 것(예, 액티비티)이 다른 것(예, 액티비티)의 이전 또는 이후에 (바로 다음 단계 또는 나중의 어떤 때라도) 일어났는가, 이들 사이에 얼마나 많은 시간이 흘렀는가, 이러한 것들이 동일한 사람에 의해서 수행되었는가 등), 여러분은 이러한 모든 것들을 결합할 수 있다.
이것은 프로세스 마이닝의 가장 강력한 파워들 중의 하나이다. 즉, 여러분은 상호작용적이고 탐색적인 방식으로 프로그래밍 없이 필터링을 위해서 행동 기반의 프로세스 패턴들을 쉽게 정의할 수 있다.
6) 프로세스 일부분들의 분해
여러분의 데이터셋을 분해하는 세 번째 방법은 단지 대상 프로세스의 어떤 일부분에 집중하는 것이다. 이것은 가위를 가지고 프로세스의 일부분을 떼어내는 것에 비유될 수 있다.
특히 매우 다양한 단계들을 가지는 매우 긴 프로세스들에 대해서 다양한 프로세스 부분들을 분해해서 이들을 별도로 분해하는 것이 유용할 수 있다.

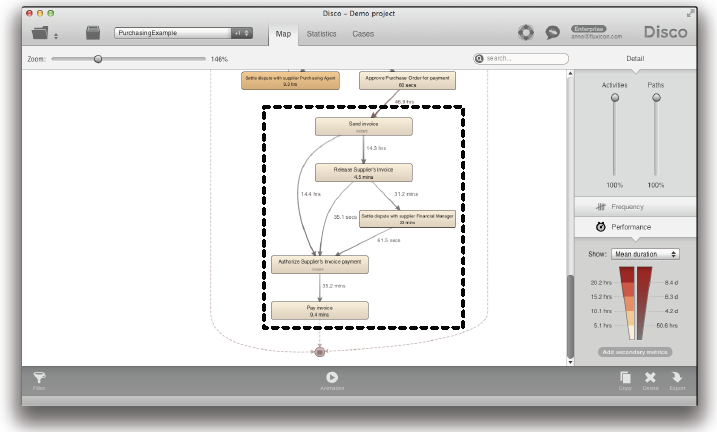
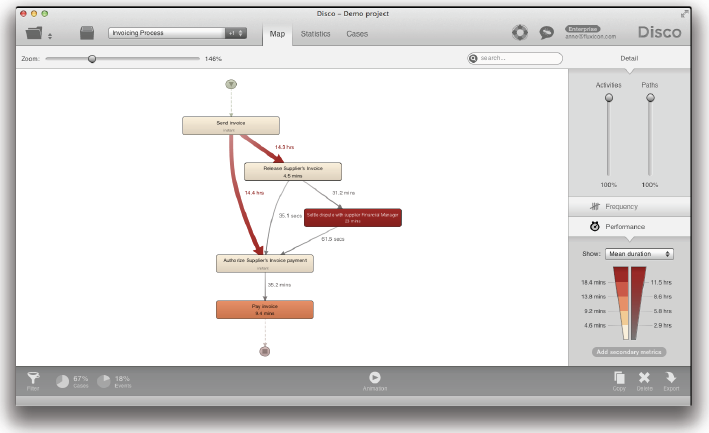
예를 들어, Disco의 샌드박스(sandbox)에 포함된 구매 프로세스를 예로 들어보자 (다음 페이지 참조). 이제 여러분은 이 프로세스의 송장처리 부분 – 송장이 보내어진 때부터 지불되기까지 (그리고 이들 사이에 발생했던 것들) – 에만 단지 집중하기를 원한다고 가정하자.
우리는 대상 프로세스에서 이 부분만을 “잘라내기”를 원한다 (우리가 초점을 두고자 하는 부분이 아래의 그림에 점선으로 표시되어 있음).
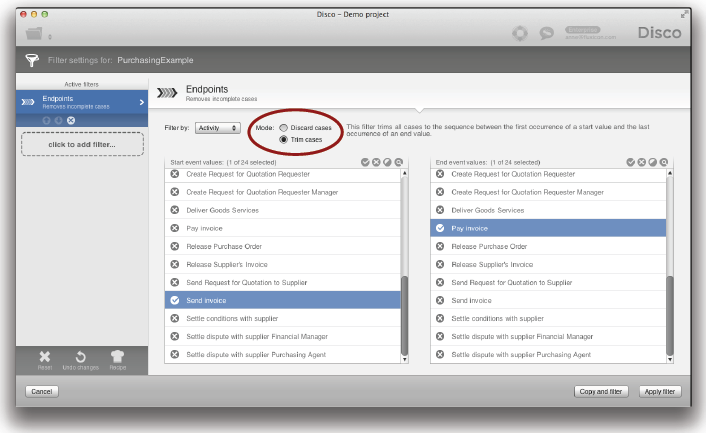
Trim 모드의 Endpoint 필터는 이것을 위해서 사용될 수 있다 (시작 이전과 종료 이후의 모든 이벤트들을 잘라내어 버리고 이들 사이의 이벤트들만 유지함):
결론적으로 우리는 이제 대상 프로세스에서 송장처리 부분을 떼어냈고, 이것을 별도로 분석할 수 있게 되었다 (아래의 그림 참조).
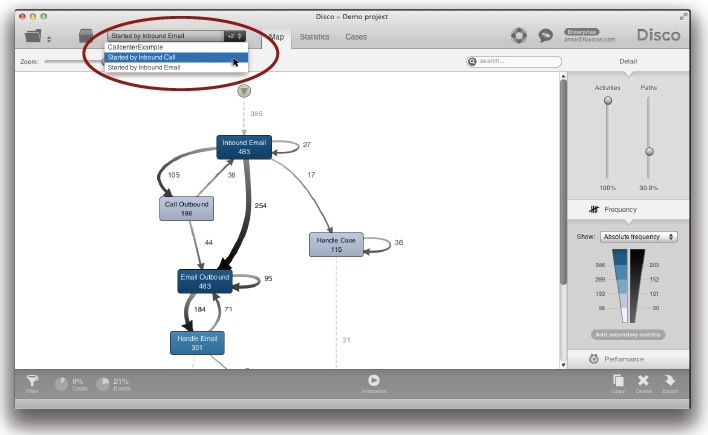
7) 다른 시작과 종료 지점들
네 번째 ‘Divide and Conquer’ 전략은 대상 프로세스의 시작과 종료 지점들을 보는 것이다. 예를 들어, 다음의 콜센터 프로세스에서 고객은 전화나 전자메일 또는 웹사이트 상의 폼을 기입함으로써 서비스 요청을 시작할 수 있다. 이러한 다양한 시작 지점들이 아래의 프로세스 맵에서 두 개의 점선으로 강조되어 있다.
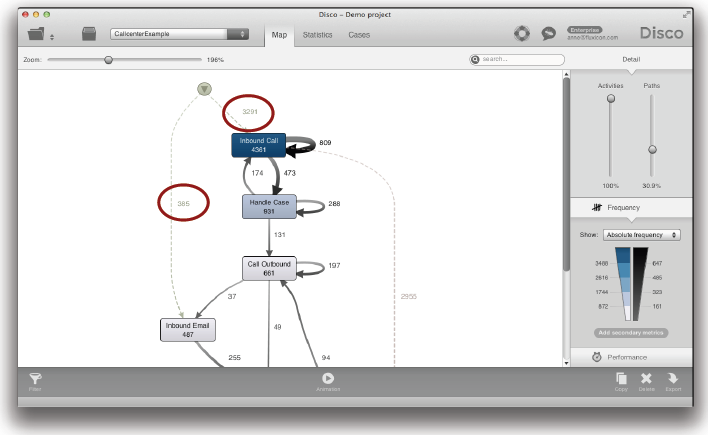
어떤 상황에서는 프로세스 자체와 프로세스에 관한 규칙들과 기대들이 프로세스가 어떻게 시작되었는가에 따라서 바뀔 수 있다. 예를 들어, 첫 번째 통화에서 고객문제를 해결하는 것 (첫 번째 통화 해결율)이 종종 목표가 될 수 있다. 그러나 이것은 전자메일 맥락에서는 덜 현실적이다. 왜냐하면 이러한 맥락은 일반적으로 고객문제를 해결하기 위해서 더욱 많은 상호작용을 요구하기 때문이다. 이런 상황이 분석에서 고려될 필요가 있다.
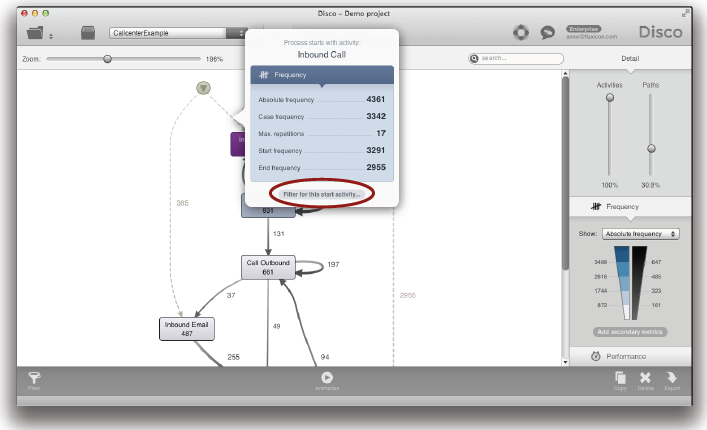
불완전한 케이스들을 제거하기 위해서 Disco의 ‘Endpoints 필터’가 이미 사용되었다. 우리는 시작과 종료 지점들에 기반을 두고 비즈니스 관점에서 데이터셋을 분리하기 위해서 ‘Endpoints 필터’를 이용하고자 한다.
[code]주의: 여러분은 상황에 따라서 데이터 정리나 분석 목적으로 동일한 필터를 사용할 수 있음을 알게 될 것이다. [/code]
‘Endpoints 필터’는 Disco에서 프로세스 맵의 점선을 클릭함으로써 쉽게 추가될 수 있다.
여러분은 사전에 설정된 필터를 직접 적용하거나 데이터셋을 별도로 유지하기 위해서 복사본을 만들 수도 있다 (아래의 그림 참조).
Part Ⅵ: Leaving Out Details
8) “거미 (Spider)” 액티비티들의 제거
단순화 전략들의 마지막 범주는 프로세스 맵을 단순하게 하기 위해서 구체적인 것들을 배제하는 것이다. 이것을 수행할 수 있는 하나의 방안은 소위 말하는 “거미” 액티비티들을 찾는 것이다. 거미 액티비티는 대상 프로세스에서 언제라도 수행될 수 있는 단계를 말한다.
최초의 서비스 반품 프로세스 데이터를 보면 여러분은 ‘Send email’과 프로세스 맵의 중심 지역들에서 나타나는 몇 개의 코멘트 액티비티들과 같은 액티비티들을 인지하게 될 것이다. 왜냐하면 이러한 액티비티들은 프로세스의 많은 다른 액티비티들과 연결되어 있기 때문이다 (아래의 그림 참조).
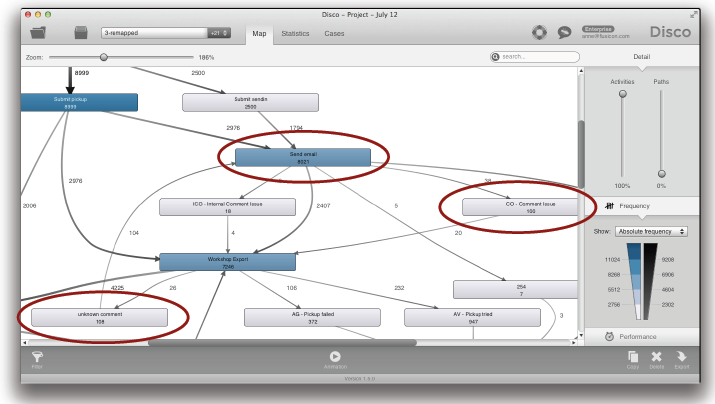
비록 이러한 활동들이 중심(거미줄의 “거미”) 위치에 나타나지만 사실 이들은 전체 프로세스에서 가장 중요하지 액티비티들이다. 프로세스 흐름에서 그들의 위치는 중요하지 않다. 왜냐하면 프로세스 수행 중의 어떤 때라도 전자메일은 보내어질 수 있고, 서비스 직원들의 코멘트들이 추가될 수 있기 때문이다.
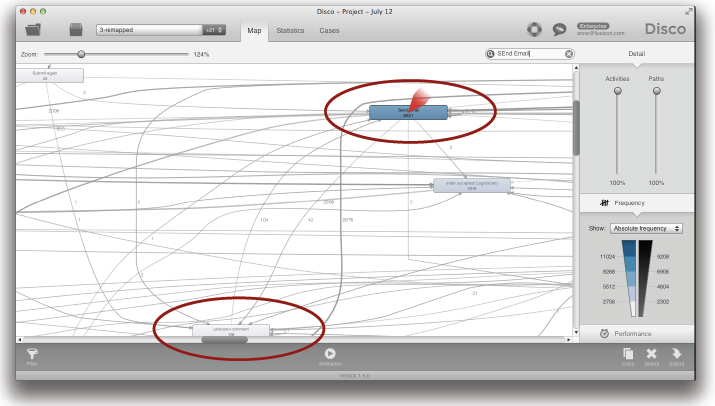
이러한 액티비티들은 때때로 프로세스의 처음이나, 끝부분, 그리고 중간에 발생할 수 있기 때문에 이들은 자신들로 향하는 많은 화살표들을 가지고 있다. 이러한 화살표들이 불필요하게 프로세스 맵을 복잡하게 만들고 있는 것이다. 만약 우리가 경로 슬라이더를 끌어 올림으로써 구체화 수준을 높인다면 프로세스 맵을 보여주는 그림은 더욱 나빠질 것이다 (다음 그림 참조).
여러분은 Attribute 필터를 추가하여 거미 이벤트들을 선택하지 않음으로써 이들을 쉽게 제거할 수 있다 (아래의 그림 참조). 표준 ‘Keep selected’ 모드에서 이 필터는 선택되지 않은 이벤트들만을 제거하고 모든 케이스들을 유지한다.
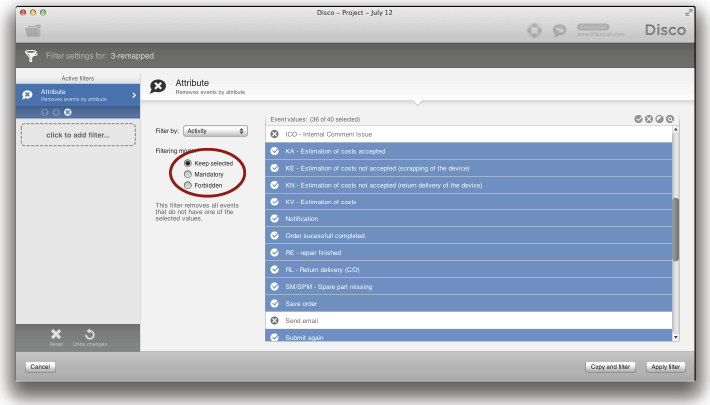
위의 필터를 적용한 결과는 혼란스러운 “거미” 활동들이 제거된 훨씬 단순한 프로세스 맵이다 (아래의 그림 참조). 그러므로 다음에 여러분이 스파게티 프로세스를 만난다면 여러분의 프로세스 분석에 어떠한 의미도 부여하지 않으면서 프로세스 맵만 복잡하게 하는 중요하지 액티비티들을 찾는 것이 필요하다.
9) 중요한 단계 (Milestone)의 액티비티들에 집중하기
구체적인 것들을 배제하는 마지막 전략은 “거미” 액티비티 전략의 반대로 가는 것이다. 즉, 여러분의 데이터셋에 포함된 전체 이벤트들의 집합에서 시작해서 무엇을 배제할 수 있는가를 찾는 대신에, 데이터에서 다양한 유형의 이벤트들을 엄격히 살펴보고 어떤 액티비티들에 집중할 것인가를 자문(自問)하는 것이다.
다양한 이벤트들이 여러분의 데이터셋에 포함되었다고 해도 이러한 이벤트들이 동등하게 중요한 것은 아니다. 종종 여러분의 로그에 기록된 액티비티들은 추상화 수준들이 다를 수 있다. 특히 여러분이 정말 많은 다양한 액티비티들을 가지고 있을 때 처음에는 가장 중요한 단계의 일부 액티비티들에 집중해서 시작하는 것이 의미가 있다.
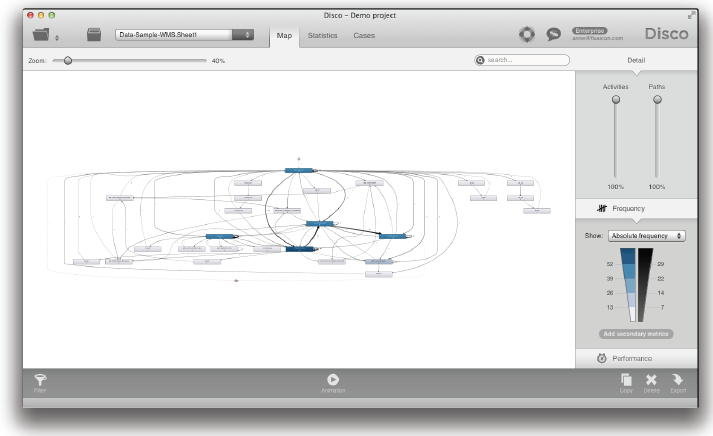
예를 들어, 아래의 익명 데이터 샘플에서 여러분은 많은 이벤트들과 ‘Load/Save’와 ‘Condition received’와 같은 구체적인 액티비티들을 가진 케이스를 볼 수 있다. 이 케이스는 또한 대상 프로세스에서 워크플로우 상태 변화들을 나타내는 다른 종류의 액티비티들(예, ‘WM_CONV_REWORK’)도 포함하고 있다.
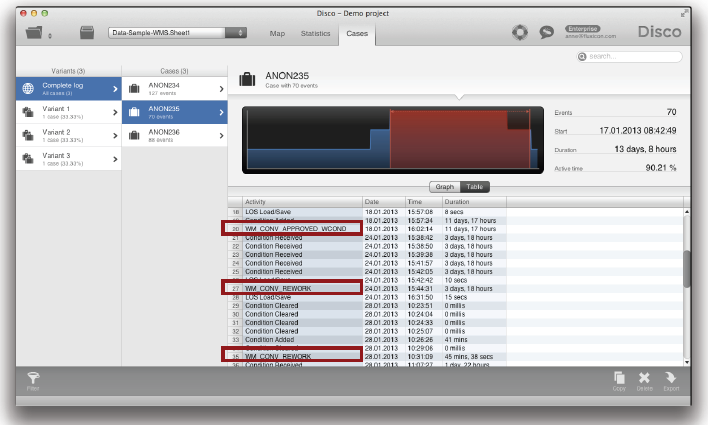
분석을 수행할 때 이러한 ‘WM_’ 액티비티들을 먼저 필터링한 후에 시작하는 것이 매우 의미가 있다. 그런 다음에 필요한 경우에 이들 사이의 구체적인 단계들을 분석에 포함하는 것이 필요하다.
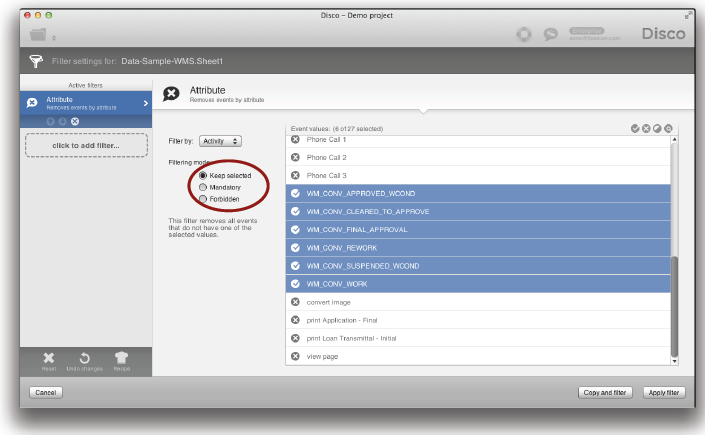
여러분은 Disco에서 이전과 같이 ‘Keep selected’ 모드에서 ‘Attribute 필터’를 이용할 수 있다. 아래와 같이, 유지하고 싶은 값들만 선택하면 된다.
매우 다양한 액티비티들을 가지는 아래의 복잡한 프로세스 맵은 …
… 선택된 중요한 단계(milestone)의 액티비티들에 대한 프로세스 흐름을 보여주도록 빠르게 단순화될 수 있다.
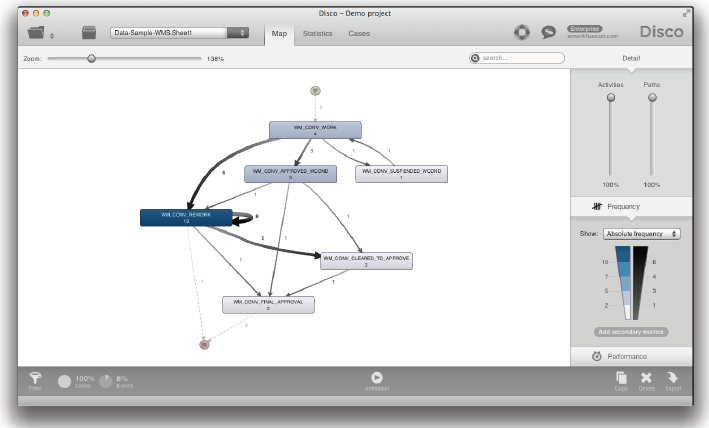
대상 프로세스에서 가장 중요한 단계의 액티비티들이 무엇인가를 잘 모른다면 여러분은 프로세스나 데이터 전문가와 함께 일부 예제 케이스들을 단계별로 차례차례 수행해 볼 수 있다. 그들은 모든 단일 상태 변화의 의미를 알지 못할 수도 있다. 그러나 도메인 지식을 가진 그들은 일반적으로 분석의 시작에 필요한 중요한 단계 이벤트들을 빠르게 선별할 수 있을 것이다.
다음과 같은 다른 방식으로 시작할 수도 있다. 즉, 도메인 전문가에게 가장 중요한 5 ~ 7 단계의 액티비티들로 프로세스를 그리도록 요청하라. 종이나 화이트 보드에 그려진 프로세스 맵은 여러분에게 비즈니스 측면에서 도메인 전문가가 간주하는 중요한 단계의 액티비티들이 무엇인가를 보여줄 것이다. 그런 다음에 여러분의 데이터로 돌아가서 이러한 중요한 단계들과 관련된 이벤트들을 어느 정도 발견할 수 있을 것이다.
중요한 단계의 액티비티들에 집중하는 것은 비즈니스와 IT의 간격을 메워주는 훌륭한 방법이다. 또한 이러한 집중은 매우 복잡한 프로세스와 방대한 데이터셋에 대한 분석을 빠르게 시작하도록 도움을 줄 수 있다.